
本页内容
p.s. GreptimeDB 已经更新到 v0.16,欢迎各位用户更新到最新版本使用。本篇文章作为 v0.15 功能的介绍在 v0.16 中依然适用。
在 v0.15 中,GreptimeDB 对 Pipeline Engine 进行了大幅的功能增强和重构,显著提升了数据预处理的灵活性与可扩展性。本次更新的亮点之一,是为 Prometheus Remote Write 与 Loki Push API 引入了原生 Pipeline 支持。
现在,用户只需在 HTTP Header 中设置 x-greptime-pipeline-name,即可将上述两类协议的数据接入 Pipeline 处理流程。
Prometheus + Pipeline 实战
我们先通过一个简单的示例,演示如何在 Prometheus Remote Write 中结合 Pipeline。
以下是 docker-compose 及 Prometheus 配置示例:
yaml
---
version: '3.8'
services:
node_exporter:
image: quay.io/prometheus/node-exporter:latest
container_name: node_exporter
command:
- '--path.rootfs=/host'
volumes:
- '/:/host:ro,rslave'
networks:
- monitoring
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- 9090:9090
depends_on:
- node_exporter
networks:
- monitoring
networks:
monitoring:yaml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['node_exporter:9100']
remote_write:
- url: 'http://host.docker.internal:4000/v1/prometheus/write'这个配置会启动一个 node_exporter 用于采集本机指标,并由 Prometheus 抓取后,通过 Remote Write 写入本地运行的 GreptimeDB。
启动 & 验证
首先使用 ./greptime standalone start 启动单机版的 GreptimeDB,然后使用 docker compose up 拉起 node-exporter 和 Prometheus。完成启动后,GreptimeDB 的日志输出中出现了建表相关的日志,使用 MySQL 客户端连接到 GreptimeDB,可以观察到指标表已经被正常创建:
plaintext
mysql> select * from `go_memstats_mcache_inuse_bytes`;
+----------------------------+----------------+--------------------+---------------+
| greptime_timestamp | greptime_value | instance | job |
+----------------------------+----------------+--------------------+---------------+
| 2025-07-11 07:28:28.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:28:43.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:28:58.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:29:13.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:29:28.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:29:43.350000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:29:58.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:30:13.349000 | 1200 | node_exporter:9100 | node-exporter |
+----------------------------+----------------+--------------------+---------------+
8 rows in set (0.06 sec)随机挑选一张表进行查询,可以得到如下结果:
注意:具体的字段根据
node-exporter采集的平台和设置会出现不同。
sql
mysql> select * from `go_memstats_mcache_inuse_bytes`;
+----------------------------+----------------+--------------------+---------------+
| greptime_timestamp | greptime_value | instance | job |
+----------------------------+----------------+--------------------+---------------+
| 2025-07-11 07:28:28.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:28:43.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:28:58.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:29:13.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:29:28.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:29:43.350000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:29:58.346000 | 1200 | node_exporter:9100 | node-exporter |
| 2025-07-11 07:30:13.349000 | 1200 | node_exporter:9100 | node-exporter |
+----------------------------+----------------+--------------------+---------------+
8 rows in set (0.06 sec)使用 Pipeline 添加 source 字段
下面给每个指标加上 source 字段。首先创建一个 Pipeline,具体配置如下:
yaml
version: 2
processors:
- VRL:
source: |
.source = "local_laptop"
.
transform:
- field: greptime_timestamp
type: time, ms
index: timestamp- VRL 处理器为每条记录新增
source字段,并赋值local_laptop; - Pipeline Version 2 允许在
transform中仅配置需要特殊处理的列(如时间索引),其他字段由上下文自动推导并补充。
Pipeline 部署
先通过 rm -rf greptimedb_data/ 清空 GreptimeDB 的数据文件,启动单机版的 GreptimeDB。接下来使用 curl -X "POST" "http://localhost:4000/v1/events/pipelines/pp" -F "file=@pipeline.yaml" 将 Pipeline 写入到 GreptimeDB,确认返回结果写入成功。然后修改 Prometheus 配置文件,增加 x-greptime-pipeline-name HTTP Header 配置,如下所示:
yaml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['node_exporter:9100'] # Replace with the actual IP/hostname of the node exporter
remote_write:
- url: 'http://host.docker.internal:4000/v1/prometheus/write'
headers:
x-greptime-pipeline-name: "pp"通过 docker compose up 启动组件,观察到日志输出后通过 MySQL 客户端连接到 GreptimeDB,对之前的表进行查询:
sql
mysql> select * from `go_memstats_mcache_inuse_bytes`;
+----------------------------+----------------+--------------------+---------------+--------------+
| greptime_timestamp | greptime_value | instance | job | source |
+----------------------------+----------------+--------------------+---------------+--------------+
| 2025-07-11 07:42:03.064000 | 1200 | node_exporter:9100 | node-exporter | local_laptop |
| 2025-07-11 07:42:18.069000 | 1200 | node_exporter:9100 | node-exporter | local_laptop |
+----------------------------+----------------+--------------------+---------------+--------------+
2 rows in set (0.01 sec)可以观察到在表中的确增加了 source 列,值就是 Pipeline 中已设定的 local_laptop。
Pipeline Engine 为数据的灵活处理提供了强有力的支持。通过将 Pipeline Engine 与 Prometheus Remote Write 请求相结合,能够在写入阶段对指标数据及其关联标签进行灵活变换,从而显著提升指标数据的处理能力与使用效率。
Loki Push API + Pipeline 实战
v0.15 同样为 Loki Push API 增加了 Pipeline 支持。只需在 Header 中设置 x-greptime-pipeline-name,即可将日志数据引入 Pipeline 处理。
以 Grafana Alloy 采集 Docker 日志为例:
docker-compose.yml:
yaml
version: '3'
services:
alloy:
image: grafana/alloy:latest
ports:
- 12345:12345
- 4317:4317
- 4318:4318
volumes:
- ./config.alloy:/etc/alloy/config.alloy
- /var/run/docker.sock:/var/run/docker.sock
command: run --server.http.listen-addr=0.0.0.0:12345 --storage.path=/var/lib/alloy/data /etc/alloy/config.alloyconfig.alloy:
plaintext
// Discover Docker containers and extract metadata.
discovery.docker "linux" {
host = "unix:///var/run/docker.sock"
}
// Define a relabeling rule to create a service name from the container name.
discovery.relabel "logs_integrations_docker" {
targets = []
rule {
source_labels = ["__meta_docker_container_name"]
regex = "/(.*)"
target_label = "service_name"
}
}
// Configure a loki.source.docker component to collect logs from Docker containers.
loki.source.docker "default" {
host = "unix:///var/run/docker.sock"
targets = discovery.docker.linux.targets
labels = {"platform" = "docker"}
relabel_rules = discovery.relabel.logs_integrations_docker.rules
forward_to = [loki.write.local.receiver]
}
loki.write "local" {
endpoint {
url = "http://host.docker.internal:4000/v1/loki/api/v1/push"
headers = {
"x-greptime-pipeline-name" = "greptime_identity",
}
}
}在 Alloy 的配置中,采集到的 Docker 日志数据会添加 platform 及 service_name 标签,然后通过 Loki 协议发送到 GreptimeDB 中,接收端会看到 x-greptime-pipeline-name 带有 greptime_identity 标签。
首先通过 ./greptime standalone start 启动机器上的 GreptimeDB 实例,在配置目录下运行 docker compose up 启动 Alloy。等待一会儿后可以看到 GreptimeDB 的日志输出建表成功后的日志行。
打开 GreptimeDB 的 Dashboard,即可使用 Logview 页面浏览日志数据:
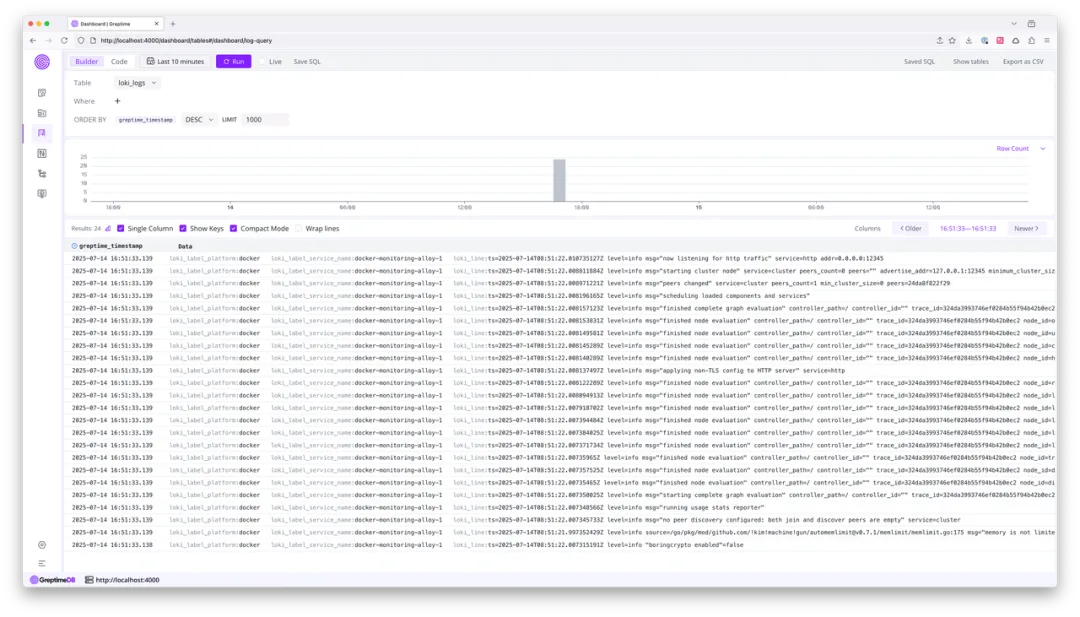
我们注意到 loki_label_service_name 这个列中的字段带了 docker-monitoring- 的前缀。现在通过 Pipeline 将其去除:
yaml
# pipeline.yaml
version: 2
processors:
- VRL:
source: |
if exists(.loki_label_service_name) {
.loki_label_service_name, err = replace(.loki_label_service_name, "docker-monitoring-", "")
}
.
transform:
- fields:
- greptime_timestamp
type: time
index: timestamp这个 Pipeline 的配置非常简单,同样使用强大的 VRL 处理器来完成这项工作。在 VRL 脚本中,首先需要判断 loki_label_service_name 字段是否存在,存在则将 docker-monitoring- 前缀替换成空字符串,并赋值给原字段。
通过 rm -rf greptimedb_data/ 清空数据之后,再次启动 GreptimeDB,并通过 curl -X "POST" "http://localhost:4000/v1/events/pipelines/pp" -F "file=@pipeline.yaml" 将 Pipeline 保存到数据库中。然后修改 Alloy 的配置文件,将 x-greptime-pipeline-name 的值修改为 pp,最后再次启动 Docker Compose。
等待 GreptimeDB 输出建表成功的日志后,再次打开 GreptimeDB Dashboard 的 Logview 进行日志查询,可以看到 loki_label_service_name 已经成功去掉了前缀:
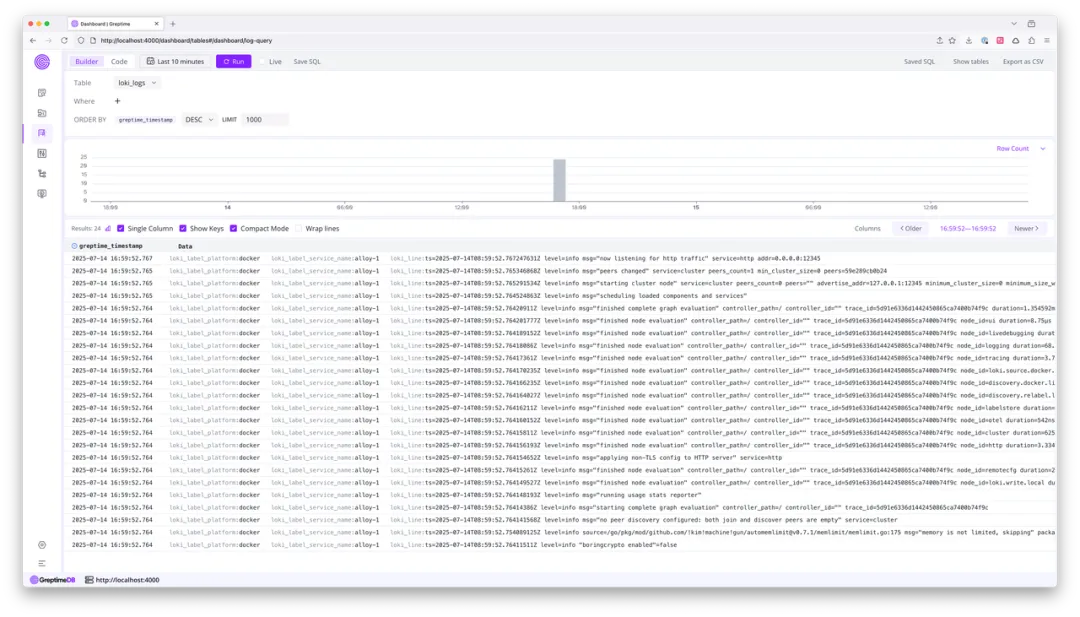
注:Docker 示例配置来源于这个文档。
以上是两个简单的 Pipeline 数据处理示例。通过与 Pipeline 和其他数据库功能(例如 Flow 引擎)的组合,用户可以实现更强大的数据自定义和预处理流程。
Auto-transform 和 Pipeline Version 2
在最初的 Pipeline 设计中,用户需要在 transform 中手动写明所有需要被持久化到数据库的字段。随着字段的数量上升和数据列的不确定性增加,这个设计使得编写 Pipeline 配置文件更加繁琐。 v0.15 引入:
- Auto-transform 模式:可省略
transform,Pipeline 引擎会自动推导字段类型并持久化(类似greptime_identity);
注:这种简化 Pipeline 编写的方式不适用于类型转换和索引添加。
- Pipeline Version 2:结合手动指定
transform转换与自动转换,允许仅对特殊字段配置转换/索引,其余字段自动推导。
注:必须手动指定时间索引列,这些列会按照配置进行处理;对于上下文中的其他字段,将尝试自动推导的方式持久化到数据库中。大大简化了 Pipeline 配置文件的编写复杂度。
相信大家在上述两个例子中已有所察觉,更详细的说明可以参考我们的文档。
VRL 处理器
Pipeline Engine 通过内置的处理器提供数据处理能力。随着数据的复杂化和用户的需求增加,现有处理器逐渐成为性能与灵活性的瓶颈。
在 v0.15 中,GreptimeDB 增加了 VRL 处理器。VRL(Vector Remap Language)是由 Vector 推出的一种面向数据处理,尤其是可观测性数据的领域特定语言(DSL)。通过编写 VRL 脚本,用户可以实现丰富多样的数据变换逻辑。
在上述两个例子中,我们使用 VRL 对输入的数据进行了字段增加和字段修改。但 VRL 的能力远不止于此——你可以在脚本中执行条件判断、字段运算、异常处理、分支逻辑,以及几乎任何可通过编程实现的数据操作。这一特性大幅增强了 Pipeline 在数据处理方面的灵活性与扩展性。
此外,Pipeline 引擎针对 VRL 及其数据类型进行了专项优化,显著降低了数据处理过程中的性能开销。借助 Dryrun API,用户可以快速验证和迭代自己的处理逻辑,灵活探索更多可能性。
Pipeline 中的 Table Hints
GreptimeDB 在创建表时支持设置一些表维度的选项,例如 ttl、skip_wal 等。由于 Pipeline 配置文件中没有相关的配置选项,且引擎会在接受写入请求时自动创建对应的表,所以无法通过 Pipeline 自动创建的表设置相关的表选项。
目前通常有两种变通方案:
1. 提前手动创建 Pipeline 目标表 手动创建可以精确设置表选项,但当 Pipeline 用于处理大规模指标数据(Metrics)时,可能涉及成百上千张表,逐一创建几乎不可行。
2. 通过 HTTP Header 传递表选项 可以在一次批量写入请求中统一附加表选项,但存在两个限制:
- 同一批次数据可能分流到不同表,无法为每张表设置不同选项;
- 如果不同表需要不同的 TTL 或其他参数,HTTP Header 无法满足差异化需求。
在 v0.15 中,GreptimeDB 为 Pipeline 引擎增加了表选项变量识别功能。只需在数据处理中设置特定命名的变量,Pipeline 引擎即可自动解析这些变量,并将对应选项注入到建表语句中。
结合 VRL 处理器,这一过程变得非常简单,例如:
yaml
processors:
- VRL:
source: |
.greptime_table_ttl = "15d"
.greptime_table_suffix, err = "_" + .id
.用户甚至可以用请求数据中的值来设置这些变量。
注:建表相关的选项仅在第一次创建表时生效;完整的变量列表可以参考这个文档。
结语
v0.15 的 Pipeline Engine 升级极大扩展了 GreptimeDB 在数据预处理、动态建表和灵活标签处理方面的能力。未来,我们将继续拓展更多数据入口的 Pipeline 支持,并在性能与易用性上持续优化。
欢迎大家试用并反馈。

