本页内容
引言
GreptimeDB 是一款开源、云原生的统一可观测性数据库,专为指标(Metrics)、日志(Logs)和链路追踪(Traces)数据而设计,能够在任何规模下提供从边缘到云端的实时洞察。
为了满足不同场景下的数据写入需求,GreptimeDB 的 Java 客户端提供了两种方式:
- Regular Insert API:低延迟,适合实时场景;
- Bulk Stream Insert API:高吞吐,面向批量写入场景。
本文将深入探讨 Bulk API 的设计与使用,并通过测试对比两种写入方式的性能差异。
Java Ingester 简介
**GreptimeDB Java Ingester 是一款轻量级、高性能的客户端,专为高效时序数据写入而设计。**它基于 gRPC 协议,提供非阻塞、纯异步的 API,具备良好的扩展性与易用性。
架构概览
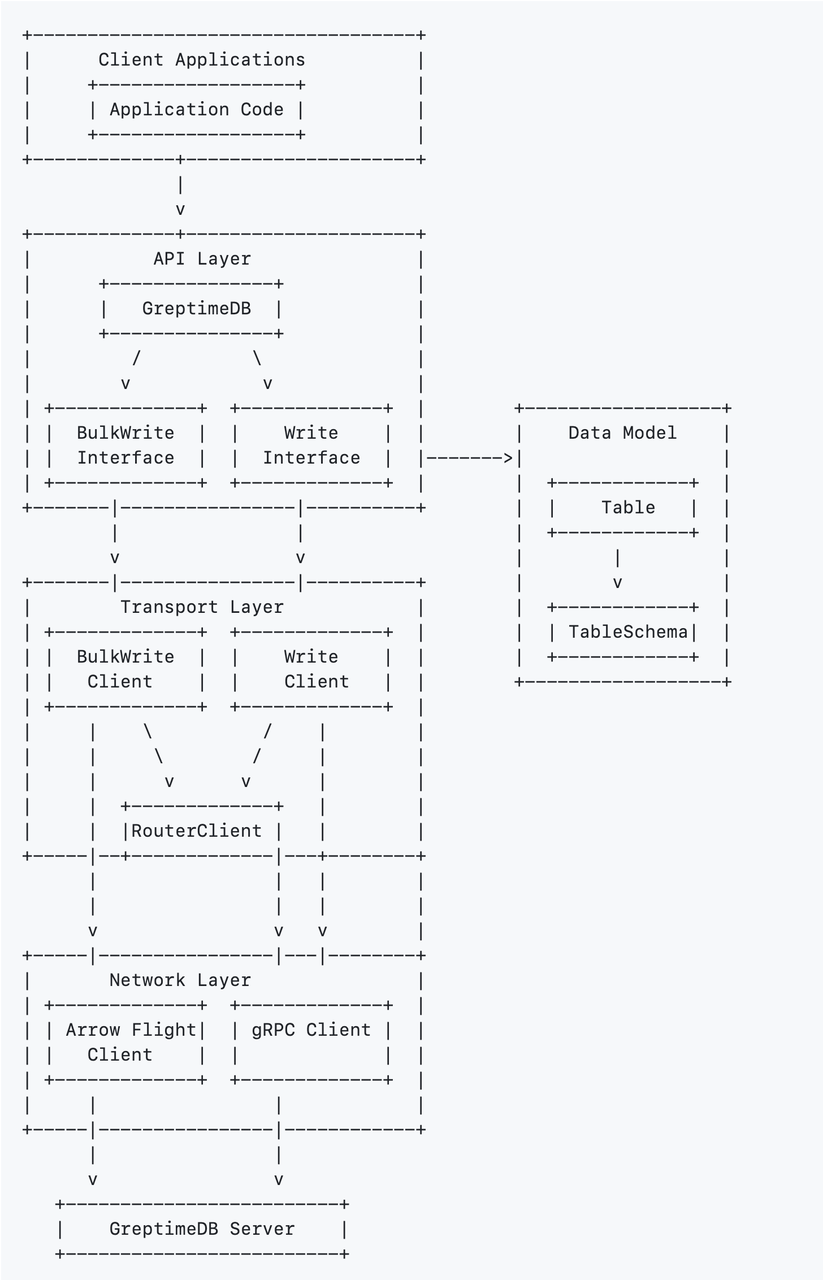
- API Layer:提供客户端应用程序与 GreptimeDB 交互的 High Level 接口;
- Data Model:使用表(Table)和 Schema 定义时序数据的组织结构;
- Transport Layer:处理通信逻辑、请求分发,并负责 Client 管理;
- Network Layer:基于 Arrow Flight 和 gRPC 进行底层协议通信。
创建客户端
GreptimeDB Ingester Java 客户端入口为 GreptimeDB 类。用户调用带有适当配置选项的静态 create 方法来创建客户端实例,全局使用单例即可:
java
String database = "public";
String[] endpoints = {"127.0.0.1:4001"};
GreptimeOptions opts = GreptimeOptions.newBuilder(endpoints, database)
.build();
// Initialize the client
GreptimeDB client = GreptimeDB.create(opts);写入方式概览
所有写入操作均基于 Table 抽象构建。使用时需要:
- 创建表结构
TableSchema; - 根据 Schema 创建
Table; - 插入行数据并提交。
⚠️ 注意:
Table不可复用,需每次重新创建;TableSchema可复用,推荐复用以减少开销。
java
// Create a table schema
TableSchema schema = TableSchema.newBuilder("metrics")
.addTag("host", DataType.String)
.addTag("region", DataType.String)
.addField("cpu_util", DataType.Float64)
.addField("memory_util", DataType.Float64)
.addTimestamp("ts", DataType.TimestampMillisecond)
.build();
// Create a table from the schema
Table table = Table.from(schema);
// Add rows to the table
// The values must be provided in the same order as defined in the schema
// In this case: addRow(host, region, cpu_util, memory_util, ts)
table.addRow("host1", "us-west-1", 0.42, 0.78, System.currentTimeMillis());
table.addRow("host2", "us-west-2", 0.46, 0.66, System.currentTimeMillis());
// Add more rows
// ..
// Complete the table to make it immutable. This finalizes the table for writing.
table.complete();常规 Insert API
适用场景: 实时应用、IoT 传感器和交互式系统。
性能特点:
- 延迟:亚毫秒级;
- 吞吐量:1k~10k 行/秒;
- 网络模式:一请求一响应(Request-Response);
- 内存占用:内存低且恒定,高并发/高吞吐可能会导致内存积压。
代码示例为:
java
// Add rows to the table
for (int row = 0; row < 100; row++) {
Object[] rowData = generateRow(batch, row);
table.addRow(rowData);
}
// Write the table to the database
CompletableFuture<Result<WriteOk, Err>> future = client.write(table);高吞吐 Bulk Stream Insert API
Bulk API 提供了一种高性能、内存高效的大规模数据写入机制,利用 Java 堆外内存管理,在批量写入数据时能够实现最佳吞吐量。
适用场景: ETL 操作、数据迁移、批处理和日志摄取。
性能特征:
- 延迟:100~10,000毫秒(批处理);
- 吞吐量:>10k 行/秒;
- 网络模式:并行请求,流式传输,一张表独占一个流;
- 内存占用:稳定,具备反压机制。
核心优势:
- 并行处理:支持多个请求同时进行,提升整体吞吐;
- 流式传输:基于 Apache Arrow Flight 流式协议;
- 压缩传输:支持 Zstd 压缩算法;
- 异步提交:非阻塞式请求提交,支持反压。
使用 Bulk Insert API 的典型模式
java
// Create a BulkStreamWriter with the table schema
try (BulkStreamWriter writer = greptimeDB.bulkStreamWriter(schema)) {
// Write multiple batches
for (int batch = 0; batch < batchCount; batch++) {
// Get a TableBufferRoot for this batch
Table.TableBufferRoot table = writer.tableBufferRoot(1000); // column buffer size
// Add rows to the batch
for (int row = 0; row < rowsPerBatch; row++) {
Object[] rowData = generateRow(batch, row);
table.addRow(rowData);
}
// Complete the table to prepare for transmission
table.complete();
// Send the batch and get a future for completion
CompletableFuture<Integer> future = writer.writeNext();
// Wait for the batch to be processed (optional)
Integer affectedRows = future.get();
System.out.println("Batch " + batch + " wrote " + affectedRows + " rows");
}
// Signal completion of the stream
writer.completed();
}Bulk API 深入解析
1. 表创建要求
- 不会自动创建表,须提前使用 SQL DDL 创建,不支持自动的 Schema 变更;
- 不支持主键列(Tag),每行数据须包含所有列。
目前 Bulk API 处于比较早期的阶段,这些限制会在未来的版本更新中逐步完善。
2. 配置选项
Bulk API 可以通过多种选项配置来优化性能:
java
BulkWrite.Config cfg = BulkWrite.Config.newBuilder()
.allocatorInitReservation(64 * 1024 * 1024L) // 自定义内存分配:初始预留 64MB
.allocatorMaxAllocation(4 * 1024 * 1024 * 1024L) // 自定义内存分配:最大分配 4GB
.timeoutMsPerMessage(60 * 1000) // 每个请求超时时间为 60 秒(侧重吞吐,建议适当容忍延迟)
.maxRequestsInFlight(10) // 并发控制:配置最多允许 10 个并发(在途)请求
.build();
// 启用 Zstd 压缩
Context ctx = Context.newDefault().withCompression(Compression.Zstd);
BulkStreamWriter writer = greptimeDB.bulkStreamWriter(schema, cfg, ctx);3. 性能调优建议
- 压缩选项:建议网络 IO 瓶颈时启用 Zstd 压缩;
- 并发度配置:
java
// 假设单实例单表写入,CPU cores = 4
// 网络绑定型 (Network-Bound):Bulk Stream Insert 主要等待网络传输
BulkWrite.Config network_bound_options = BulkWrite.Config.newBuilder()
.maxRequestsInFlight(8) // 推荐 8-16,充分利用网络带宽
.build();
// CPU 密集型 (CPU-Intensive):如果数据写入前需要大量计算处理
BulkWrite.Config network_bound_options = BulkWrite.Config.newBuilder()
.maxRequestsInFlight(8) // 推荐 CPU 核心数
.build();
// 混合负载:根据实际瓶颈调整
BulkWrite.Config network_bound_options = BulkWrite.Config.newBuilder()
.maxRequestsInFlight(8) // 在网络和 CPU 之间平衡
.build();- 批次大小:Ingester 的
Table本质上是一个buffer。小批次适合低延迟场景(实时性要求较高但数据量较小);大批次适合高吞吐场景,但是会加大延迟。
性能对比实验
为了更好地说明 Bulk API 的使用场景,我们在 greptimedb-ingester-java 仓库中构建了一个简单的日志场景测试工具。
该工具提供了 TableDataProvider,一个为性能测试设计的高性能日志数据生成器,能够生成包含 15 个字段的合成日志数据,模拟真实分布式系统的日志场景,表结构如下👇
表结构
sql
CREATE TABLE IF NOT EXISTS `my_bench_table` (
`log_ts` TIMESTAMP(3) NOT NULL,
`business_name` STRING NULL,
`app_name` STRING NULL,
`host_name` STRING NULL,
`log_message` STRING NULL,
`log_level` STRING NULL,
`log_name` STRING NULL,
`uri` STRING NULL,
`trace_id` STRING NULL,
`span_id` STRING NULL,
`errno` STRING NULL,
`trace_flags` STRING NULL,
`trace_state` STRING NULL,
`pod_name` STRING NULL,
TIME INDEX (`log_ts`)
)
ENGINE=mito数据特点
关键特性:大型 log_message 字段
- 目标长度:2,000 字符;
- 内容生成:基于模板的系统,根据日志级别生成不同类型的消息;
字段基数/维度分布
- 高基数字段(近乎唯一)
trace_id,span_id:使用 64 位随机数生成 ;log_ts:基于毫秒时间戳。 低基数等字段不在这里一一列举。
运行 Benchmark 测试
- 启动 GreptimeDB;
- 建表;
- 按照顺序启动 Bulk &Regular API Benchmark;
- 启动命令:
java
# Bulk API Benchmark
运行 io.greptime.bench.benchmark.BatchingWriteBenchmark
# Regular API Benchmark
运行 io.greptime.bench.benchmark.BatchingWriteBenchmark- 我的本地测试结果如下:
| API 类型 | 吞吐量 | 总耗时 | 提升幅度 |
|---|---|---|---|
| Bulk API | 180,962 rows/s | 27.630 s | +83% |
| Regular API | 98,868 rows/s | 50.572 s | 基准线 |
结果表明:
- Bulk API 吞吐量提升约 80%+;
- Regular API 适合小规模、低延迟场景;
- Bulk API 适合高吞吐、大批量写入场景。
Bulk API 结果
java
- === Running Bulk API Log Data Benchmark ===
- Setting up bulk writer...
- Starting bulk API benchmark: RandomTableDataProvider
- Table: my_bench_table (14 columns)
- Target rows: 5000000
- Batch size: 65536
- Parallelism: 4
// 省略无关日志...
- → Batch 1: 65536 rows processed (47012 rows/sec)
- → Batch 2: 131072 rows processed (75199 rows/sec)
// 省略部分过程日志 ...
- → Batch 73: 4784128 rows processed (180744 rows/sec)
- → Batch 74: 4849664 rows processed (180748 rows/sec)
- → Batch 75: 4915200 rows processed (180699 rows/sec)
- Completing bulk write operation, signaling end of transmission
- Waiting for server to complete processing
- → Batch 76: 4980736 rows processed (180972 rows/sec)
- → Batch 77: 5000000 rows processed (181015 rows/sec)
- Finishing bulk writer and waiting for all responses...
- All bulk writes completed successfully
- Cleaning up data provider...
- Bulk API benchmark completed successfully!
- === Benchmark Result ===
- Table: my_bench_table
-
- Provider Rows Duration(ms) Throughput Status
- --------------------------------------------------------------------------
- RandomTableDataProvider 5000000 27630 180962 r/s SUCCESSRegular API 结果
java
- === Running Batching API Log Data Benchmark ===
- Setting up batching writer...
- Starting batching API benchmark: RandomTableDataProvider
- Table: my_bench_table (14 columns)
- Target rows: 5000000
- Batch size: 65536
- Concurrency: 4
// 省略无关日志 ...
- → Batch 1: 65536 rows processed (17415 rows/sec)
- → Batch 2: 131072 rows processed (32031 rows/sec)
// 省略部分过程日志 ...
- → Batch 73: 4784128 rows processed (98586 rows/sec)
- → Batch 74: 4849664 rows processed (98638 rows/sec)
- → Batch 75: 4915200 rows processed (98776 rows/sec)
- → Batch 76: 4934464 rows processed (97574 rows/sec)
- Finishing batching writer and waiting for all responses...
- → Batch 77: 5000000 rows processed (98868 rows/sec)
- All batching writes completed successfully
- Cleaning up data provider...
- Batching API benchmark completed successfully!
- === Benchmark Result ===
- Table: my_bench_table
-
- Provider Rows Duration(ms) Throughput Status
- --------------------------------------------------------------------------
- RandomTableDataProvider 5000000 50572 98868 r/s SUCCESSAPI 使用选择指南
| 使用场景(特征) | 推荐 API | 理由 |
|---|---|---|
| 实时监控告警 | Regular API | 低延迟,立即响应 |
| IoT 传感器数据 | Regular API | 数据量小,实时性强 |
| 交互式仪表板 | Regular API | 即时反馈 |
| ETL 数据管道 | Bulk API | 数据量大,可容忍延迟 |
| 日志收集系统 | Bulk API | 高吞吐量,批处理 |
| 历史数据迁移 | Bulk API | 一次性大量数据操作 |
总结
GreptimeDB 提供两种互补的写入方式:
- Regular API:低延迟,适合实时性要求高的小规模写入;
- Bulk API:高吞吐,适合大规模批量导入和日志处理。
开发者可根据业务需求灵活选择或组合使用,从而在不同场景下兼顾系统的可扩展性与高性能目标。

