本页内容
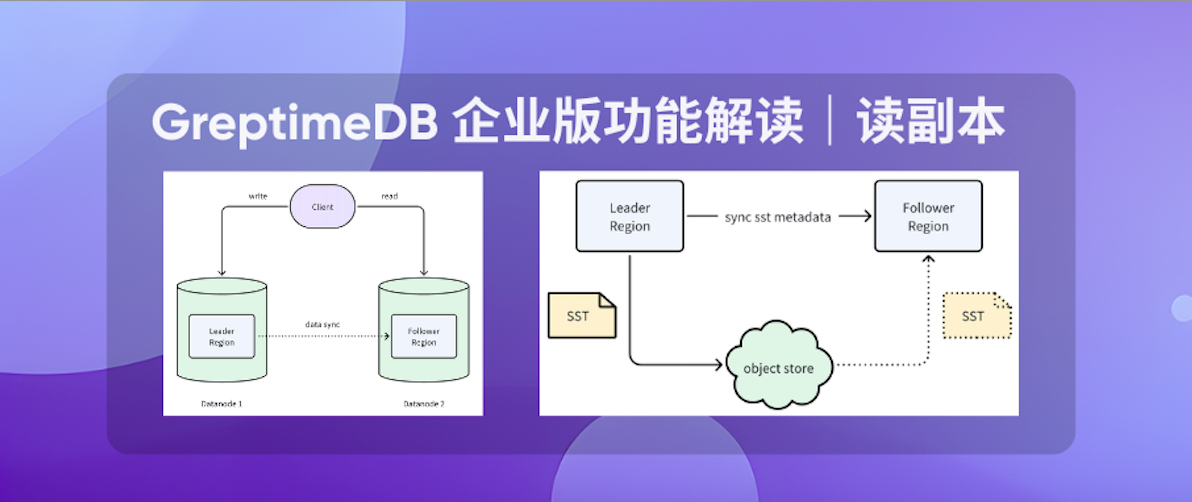
读副本(Read Replica)是 GreptimeDB 企业版提供的一项核心功能,旨在提高数据库系统的整体读写性能和水平扩展能力。在该机制下,客户端所有写入操作首先落在 Leader Region,随后 Leader 会将数据同步至 Follower Region。Follower 仅承担读取职责,相当于 Leader 的只读副本。
Leader 与 Follower Region 部署在不同的 Datanode 节点上,实现了读写请求的分离,从而避免系统资源的相互争抢,提供更流畅的整体使用体验:
基于 GreptimeDB 企业版的存算分离架构,数据在不同副本之间的同步几乎没有额外开销。同时,读副本能够在无感延迟的情况下读取最新写入的数据。下面将分别介绍数据同步与数据读取的实现原理。
原理解析
数据同步
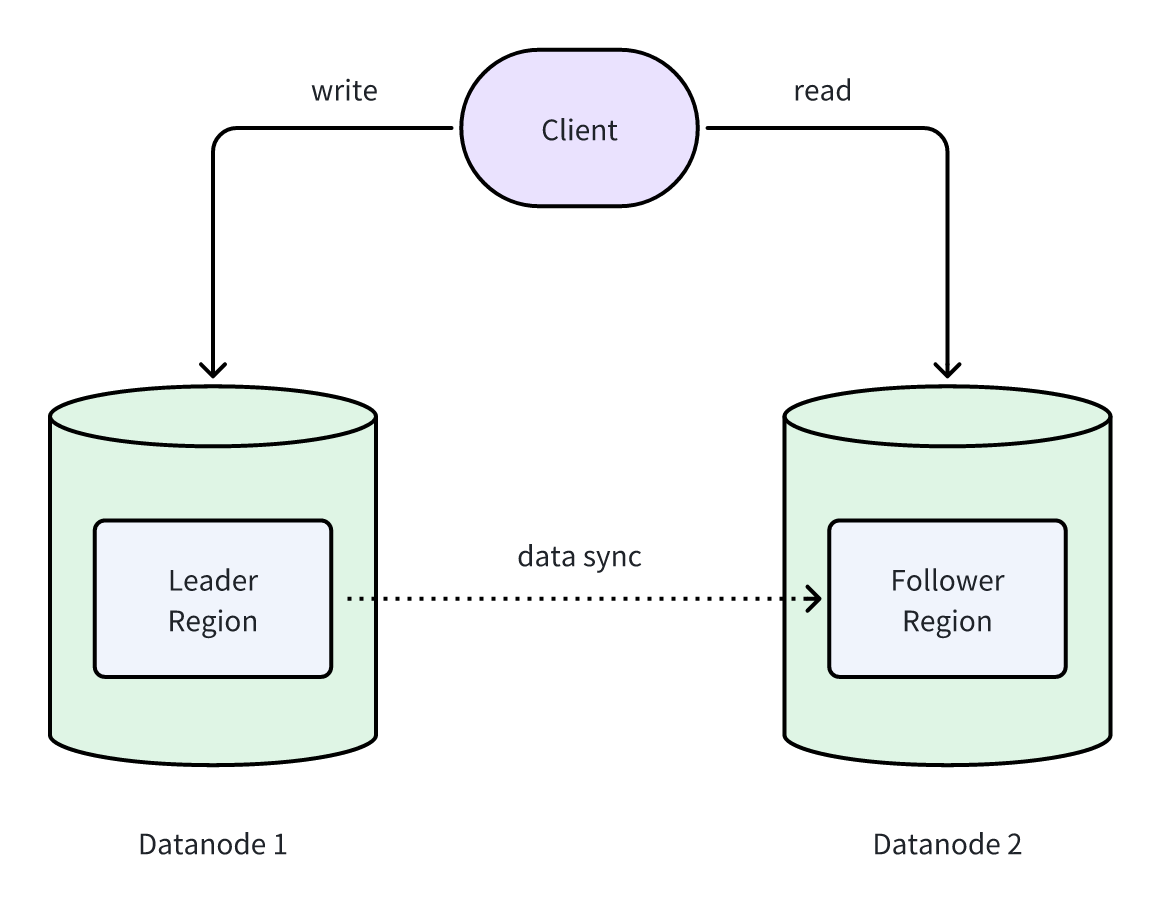
在 GreptimeDB 企业版中,所有数据最终以 SST 文件存储在对象存储中。因此,Leader 与 Follower Region 之间的数据同步无需复制整个 SST 文件,只需同步元信息(metadata)。
由于元信息体量远小于 SST 文件,Leader 可以轻量地将其同步给 Follower。一旦元信息同步完成,Follower 即可“拥有”相同的 SST 文件,从而具备读取数据的能力:
在实现细节上,SST 文件元信息会持久化在一个特殊的 manifest 文件中,并与 SST 文件一同存放在对象存储里。每个 Manifest 文件都有唯一的版本号。
Leader 与 Follower 的数据同步,本质上就是同步 Manifest 文件的版本号。该版本号仅为一个整型数值,因此同步代价极低。Follower 获取到版本号后,会直接从对象存储拉取对应的 Manifest 文件,从而得到最新的 SST 元信息。
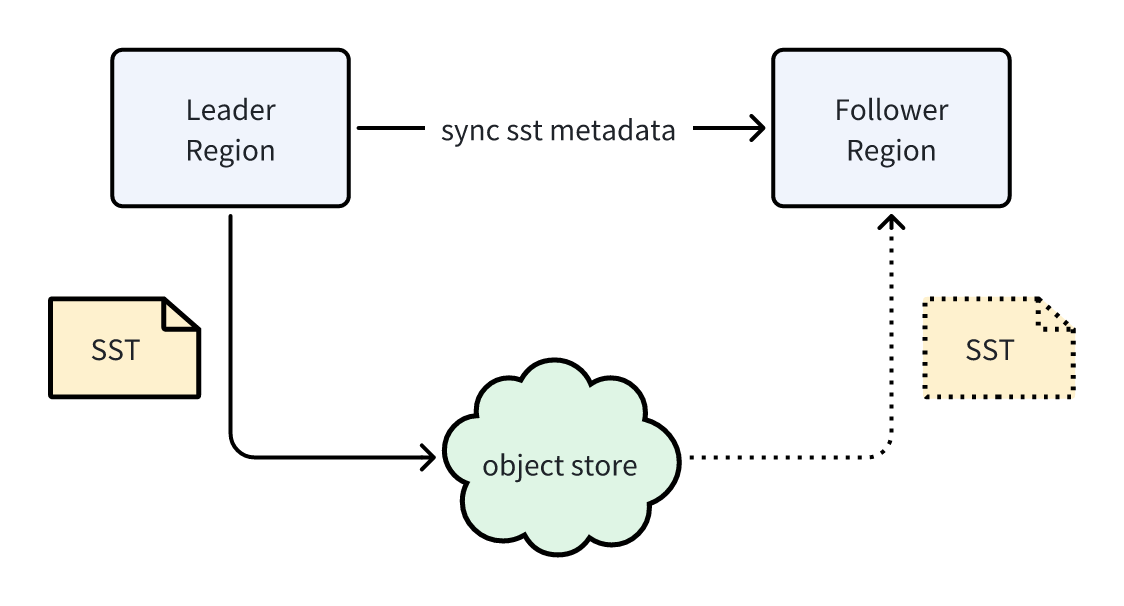
这一过程依赖于 Region 与 Metasrv 的心跳机制:
- Leader 在心跳消息中携带 Manifest 版本号;
- Metasrv 再将该版本号下发给 Follower。
在仅依赖 SST 文件同步的场景下,读副本能看到的数据延迟取决于 Leader 与 Follower 的心跳间隔之和。
例如,当两个 Region 的心跳间隔均为默认的 3 秒时,Follower 只能读取到 3~6 秒前 Flush 到对象存储的数据的数据。 若应用对数据时效性要求不高,此方案已足够。但若希望读副本能 实时反映最新写入,则需要结合下文的数据读取机制。
数据读取机制
最新写入的数据会先保存在 Leader Region 的 Memtable 里。为了让读副本也能实时读取这些数据,Follower 会通过内部 gRPC 接口 从 Leader 拉取 Memtable 中的数据。
最终,Follower 将两部分数据进行合并:
- 通过 Manifest 同步获得的 SST 文件;
- 从 Leader 拉取的 Memtable 最新数据。
这样,Follower 就能向客户端返回与 Leader 一致的、包含最新写入的数据集:
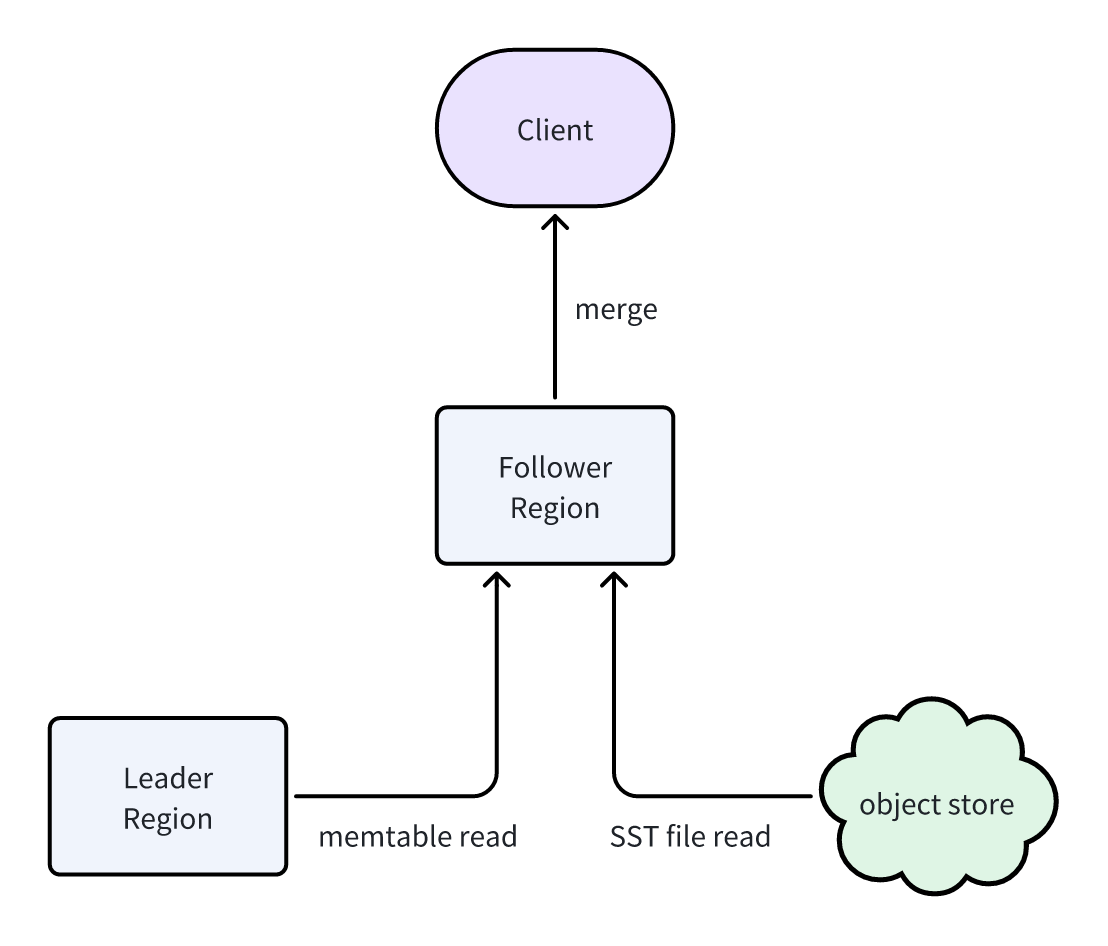
这种方式虽然会给 Leader 带来一定读请求,但由于 memtable 数据完全驻留在内存中且容量有限,对 Leader 的压力非常轻。
增加读副本
在 GreptimeDB 企业版中,增加读副本的操作非常简单,只需一条 SQL 命令:
sql
ADMIN ADD_TABLE_FOLLOWER(<table_name>, <follower_datanodes>)调用 GreptimeDB 的增加读副本函数,需要两个参数:
table_name:表名;follower_datanodes:目标 Follower Region 所在的 Datanode ID 列表(逗号分隔)。
例如,在一个拥有 3 个 Datanode 的企业集群中,创建一张表:
sql
CREATE TABLE foo (
ts TIMESTAMP TIME INDEX,
i INT PRIMARY KEY,
s STRING,
) PARTITION ON COLUMNS ('i') (
i <= 0,
i > 0,
);通过 information_schema 查询 Region 相关信息:
sql
SELECT table_name, region_id, peer_id, is_leader FROM information_schema.region_peers WHERE table_name = 'foo';
+------------+---------------+---------+-----------+
| table_name | region_id | peer_id | is_leader |
+------------+---------------+---------+-----------+
| foo | 4402341478400 | 1 | Yes |
| foo | 4402341478401 | 2 | Yes |
+------------+---------------+---------+-----------+结果显示表 foo 拥有 2 个 Region,分别位于 Datanode 1 和 2 上。
接下来为该表增加读副本:
sql
ADMIN ADD_TABLE_FOLLOWER('foo', '0,1,2');再次查询信息,可以看到已经成功生成 Follower Region:
sql
SELECT table_name, region_id, peer_id, is_leader FROM information_schema.region_peers WHERE table_name = 'foo';
+------------+---------------+---------+-----------+
| table_name | region_id | peer_id | is_leader |
+------------+---------------+---------+-----------+
| foo | 4402341478400 | 1 | Yes |
| foo | 4402341478400 | 0 | No |
| foo | 4402341478401 | 2 | Yes |
| foo | 4402341478401 | 1 | No |
+------------+---------------+---------+-----------+查询结果,两个 Follower Region 分别在 Datanode 1 和 2 上。
使用读副本
客户端可通过设置读偏好(Read Preference) 来控制查询目标是 Leader 还是 Follower Region。在 JDBC(MySQL / PostgreSQL 协议)连接中,可执行以下命令:
sql
-- 当前连接的读请求指向 Follower Region
-- 如果没有 Follower Region,会报错给客户端:
SET READ_PREFERENCE='follower'
-- 当前连接的读请求优先使用 Follower Region
-- 如果没有 Follower Region,则读请求 fallback 到 Leader Region(客户端不报错):
SET READ_PREFERENCE='follower_preferred'
-- 当前连接的读请求指向 Leader Region:
SET READ_PREFERENCE='leader'以上面创建的表为例,插入一些数据:
sql
INSERT INTO foo (ts, i, s) VALUES (1, -1, 's1'), (2, 0, 's2'), (3, 1, 's3');设置为从 Follower Region 读取数据:
sql
SET READ_PREFERENCE='follower';结果:
sql
SELECT * FROM foo ORDER BY ts;
+----------------------------+------+------+
| ts | i | s |
+----------------------------+------+------+
| 1970-01-01 00:00:00.001000 | -1 | s1 |
| 1970-01-01 00:00:00.002000 | 0 | s2 |
| 1970-01-01 00:00:00.003000 | 1 | s3 |
+----------------------------+------+------+可以看到,读副本正确返回了最新写入的数据。
总结
GreptimeDB 企业版的读副本功能不仅实现了读写分离,显著提升了系统的吞吐能力与扩展性,还能在保证低成本的同时,确保数据的时效性。对于高并发查询、报表分析等以读为主的场景,读副本提供了强大的能力支撑,是企业用户实现性能提升与成本优化的关键特性。

