
本页内容
🎥 回看完整演讲
新的“大数据”:Observability
近几年,Observability(可观测性)数据是继“大数据”之后又一高速增长的领域。开发者会从应用程序和其运行环境中采集各种数据,用于 DevOps 闭环中的监测、诊断与优化,这些数据的体量与多样性在持续扩大。
这一领域的生态极为复杂,服务、协议、格式和数据库层出不穷。为了帮助理解可观测性数据的完整流动路径,我们提出了一个 “V 模型(V Model)”,展示从数据源到数据应用的全流程。
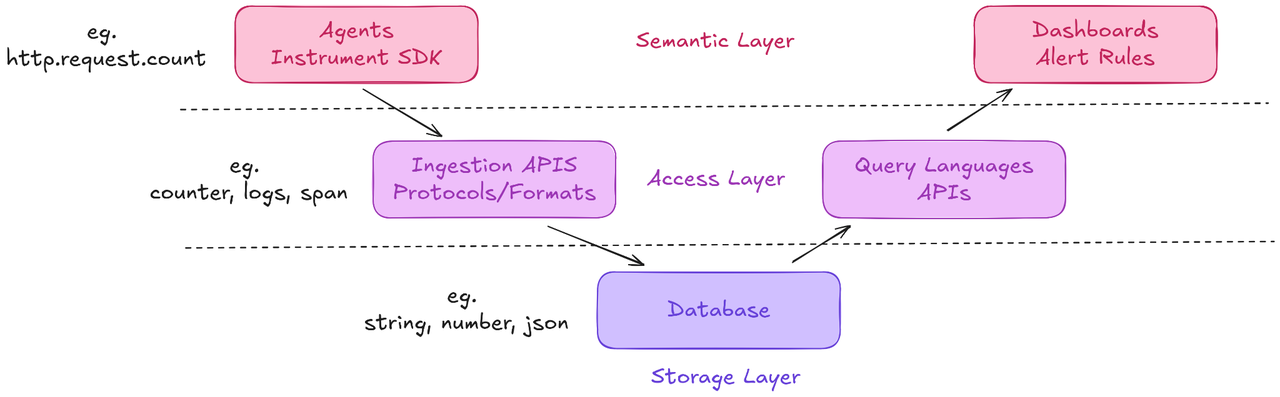
图示左侧,数据来自于应用或代理(agent),通过 API 完成数据写入(ingestion);图示右侧,通过数据库查询并返回数据,再通过可视化面板展示结果。
此外,我们还将整个 Observability 技术栈划分为三层结构:
1. 语义层(Semantic Layer)
定义采集的数据类型及其含义,并决定这些数据的使用方式。像 DataDog 这样端到端可观测性服务,就以此层为主要交互界面。
2. 数据访问层(Data Access Layer)
负责数据的写入与查询,是应用程序与底层数据库之间的桥梁。常见的开放标准 OpenTelemetry 就主要在这一层发挥作用。
3. 存储层(Storage Layer)
底层的数据库层,用于真正存放与管理数据。我们在这一层可以使用多种数据库:通用型、分析型或特定的时序、键值数据库等,例如 GreptimeDB。
重新思考传统的 O11y 数据架构
目前的 Observability 数据管道基本沿袭了传统监控系统的思路,将数据分为三类:Metrics(指标)、Logs(日志) 和 Traces(链路追踪)。
每种数据类型都有一套自己独立的采集、传输与存储流程。
这种割裂的架构带来了几个典型问题:
- 数据孤岛:不同类型的数据无法关联分析;
- 缺乏原始数据 :聚合或抽样导致信息丢失;
- 静态采集:指标固定,缺乏灵活性和快速反馈机制。
这些问题使我们难以充分挖掘和利用可观测性数据的潜力。
Observability Data Lake:不仅是数据湖
仅仅将底层数据库替换为对象存储(Object Storage)并采用“存算分离”的架构,并不能真正解决这个问题。一个真正的 Observability Data Lake,关键在于让数据更可用、更灵活。
为了解决传统架构的三大问题,我们提出了三条实践路径:
1. 尽可能保留原始数据
直接从应用层采集未经聚合的原始数据,通过数据管道在后端生成 metrics 与 traces,并统一写入数据湖。
2. 将聚合过程后移到数据库中
不再在应用内存中进行聚合,而是交给数据库执行。这样可简化数据库中数据的结构,并允许在查询时动态重组聚合逻辑。
3. 快速调整聚合逻辑
聚合逻辑后移后,更新规则的方式更加灵活:
- 更新数据库中的物化视图(Materialized View) 规则;
- 更新查询语句;
- 将反馈周期从数天缩短到数秒。
在我们的深入中,Observability Data Lake 不只是一个新的存储层,而是一种关于可观测性数据的新思维:
它不再被限制为“指标、日志、链路数据”这三类,而是一个统一、动态的数据集,支持快速迭代、深度洞察,并能为 AI 提供更高质量的输入。
这意味着,我们关注的不只是“数据存在哪里”,更重要的是——如何实时地转换、查询与学习这些数据。
实践要点与启示
要构建一个功能完备的 Observability Data Lake,我们认为需要关注以下几个方面:
1. 基础设施层面
- 支持海量原始数据的存储与查询;
- 借助对象存储实现低成本、长期持久化;
- 构建弹性、可扩展、灵活的架构。
2. 数据采集层面
从数据源采集带有上下文信息的原始数据,为后续分析提供更多维度。
3. 数据模型层面
将三大支柱(metrics、logs、traces)抽象为不同的“视图(views)”,而非独立系统。
4. 分析层面
支持探索性数据分析(Exploratory Data Analysis,EDA),帮助识别未知问题(Unknown-unknown)。
5. 智能化方向
为 AI 应用提供更高质量、更丰富上下文的数据输入,构建智能化的数据基础设施

