
本页内容
- Speaker:Ruihang Xia
- Editor:Dennis Zhuang
前言
大家好,我是 Ruihang(GitHub ID: @waynexia),目前在 GreptimeDB 担任研发工程师,同时也是 Apache DataFusion 的 PMC 成员。今天想和大家分享一些我在 DataFusion 社区中学习到的基础优化技巧。
虽然标题中有"基础"二字,但请不要误会——这里不会涉及什么"天顶星科技"。今天分享的内容都是一些相对简单但实用的优化方法,这些技巧不仅适用于 SQL 引擎,也可以应用到大多数 Rust 项目中。
关于 DataFusion
在深入优化细节之前,先简单介绍一下 Apache DataFusion。按照官方描述,DataFusion 是一个基于 Apache Arrow、用 Rust 编写的可扩展查询引擎。如果要类比的话,它类似于 DuckDB——一个 library-style 的分析型查询引擎。
DataFusion 目前已经在各种项目和场景中得到广泛应用,GitHub 上约有 3,000 个仓库在使用它。在性能方面,DataFusion 在各类 Benchmark(如 ClickBench)中也表现不俗。从项目活跃度来看,从 2016/2017 年项目启动至今,社区活跃度翻了好几倍。
不过需要说明的是,今天分享的优化技巧并不直接关联那些 Benchmark 榜单。我们关注的是更"基础"的东西——那些可以在各种 Rust 项目中复用的优化思路。
优化一:善用 HashMap
HashMap 本身就是一种优化
让我们从最常见的 HashMap 开始。很多时候,使用 HashMap 本身就是一种优化手段。
我最近在 GreptimeDB 中发现了一段有趣的代码(相关 PR: GreptimeDB#6487):
rust
fn set_indexes(&mut self, options: Vec<SetIndexOption>) -> Result<()> {
for option in options {
if let Some(column_metadata) = self
.column_metadatas
.iter_mut()
.find(|c| c.column_schema.name == *option.column_name())
{
Self::set_index(column_metadata, option)?;
}
}
Ok(())
}这段代码需要处理两个数组:一个是 options,一个是 columns。原始实现直接写出了一个 O(n²) 的算法——对每个 option 遍历一遍 columns 数组。当列数或 option 数量增多时,性能会急剧下降。
优化方法很直接:先把较小的数组收集到 HashMap 中,然后遍历另一个数组时用 O(1) 的时间在 HashMap 中查找。这样就能轻松将复杂度从 O(n²) 降到 O(n):
rust
fn set_indexes(&mut self, options: Vec<SetIndexOption>) -> Result<()> {
let mut set_index_map: HashMap<_, Vec<_>> = HashMap::new();
for option in &options {
set_index_map
.entry(option.column_name())
.or_default()
.push(option);
}
for column_metadata in self.column_metadatas.iter_mut() {
if let Some(options) = set_index_map.remove(&column_metadata.column_schema.name) {
for option in options {
Self::set_index(column_metadata, option)?;
}
}
}
Ok(())
}这个例子虽然比较初级,但它提醒我们:在需要频繁查找的场景中,HashMap 往往是第一选择。
聚合与连接场景
在 SQL 计算引擎中,HashMap 最常用的场景是聚合(Aggregation)和连接(Join)操作。
以聚合为例,这是从 KiteSQL 项目中摘录的一段代码:
rust
let mut group_hash_accs: HashMap<Vec<DataValue>, Vec<Box<dyn Accumulator>>> =
HashMap::new();
...
let entry = match group_hash_accs.entry(group_keys) {
Entry::Occupied(entry) => entry.into_mut(),
Entry::Vacant(entry) => {
entry.insert(throw!(create_accumulators(&agg_calls)))
}
};
...
for (acc, value) in entry.iter_mut().zip_eq(values.iter()) {
throw!(acc.update_value(value));
}这个实现非常直观:对于 GROUP BY 中的每个键值组合,用 HashMap 存储对应的聚合状态(key 是 group by 的值,value 是要计算的累加器)。
进阶:优化 HashMap 实现
即使使用了 HashMap,我们还可以做进一步优化:
1. 替换哈希函数实现
最简单通用的方法是更换 HashMap 的实现。比如使用 ahashmap,它提供了与标准库 HashMap 完全相同的 API,可以做到 drop-in 替换,但性能往往更好。
2. 奇技淫巧:复用哈希种子
这是一个很有意思的优化(DataFusion#16165):DataFusion 在做聚合时需要两步 HashMap 计算——先在小批次中做局部聚合,然后再合并成最终结果。
优化方法是让两个 HashMap 使用相同的随机种子:
rust
/// Hard-coded seed for aggregations to ensure hash values differ
/// from `RepartitionExec`, avoiding collisions.
const AGGREGATION_HASH_SEED: ahash::RandomState =
ahash::RandomState::with_seeds('A' as u64, 'G' as u64, 'G' as u64, 'R' as u64);
...
/// Make different hash maps use the same random seed.
random_state: crate::aggregates::AGGREGATION_HASH_SEED就这么简单的改动,在 ClickBench 的端到端测试中,大多数 case 能带来约 10% 的性能提升。
原因是:如果复用相同的哈希函数和种子,那么在局部 HashMap 中计算出的桶分布可以直接保留到合并阶段,减少了 rehash 等开销。
3. 深度定制:基于 HashTable 自建
DataFusion 在聚合器中已经部分替换掉了标准的 HashMap,改为基于更底层的 hash table API 手动实现,叫做 ArrowBytesMap。它的 key 固定是 binary 或 string 类型。
为什么要这么做?因为 DataFusion 有一个明显的使用模式:每次做完 HashMap 计算后,都要把所有的 key 取出来,拼成一个 bytes array 用于下一步计算。如果直接用 HashMap,就需要额外的转换步骤,开销不小。
基于 hash table 的底层 API(使用者负责计算哈希、维护哈希值、维护索引,底层只提供冲突处理、找槽等核心算法),我们能获得更多控制权:
- 批量化操作:比如 DataFusion
ArrowBytesMap中的这段插入代码,先批量化计算哈希值,然后寻找适当的位置插入。 - 减少中间分配: 直接在内部维护类似
Vector或 array builder 的结构,输入值直接 append 进去,后续通过 slices 引用,避免不必要的内存分配。 - 便利的 API: 提供批量输入输出、直接 collect 成 Arrow Array 等接口。
当然,我并不是鼓励大家在所有场景都自己实现 HashMap。但当你的代码有明显的使用模式,且该部分确实是性能瓶颈时,使用更底层的 hash table API、将业务逻辑与数据结构深度结合,往往能带来显著提升。
优化二:代码特化(Specialization)
项目可能是通用的,但代码可以不那么通用。针对不同场景做特化优化,往往能带来可观的性能提升。
案例一:字符串处理特化
你处理的字符串是什么类型?是纯 ASCII 还是包含中文?是否是 ASCII 和中文混合?
大家知道,UTF-8 的字长是可变的,导致在 UTF-8 字符串中按下标取值是 O(n) 的(需要一个个数过去)。但 ASCII 不同——每个字符都是固定 1 字节,第 N 个字符就是固定偏移量。
基于这个假设,我们能做很多优化。这里列举三个 DataFusion 中的例子:
- Faster reverse() string function for ASCII-only case #14195 性能提升 30%~84%
- Faster strpos() string function for ASCII-only case #12401 性能提升 50%
- Specialize ASCII case for substr() #12444 对于仅有 ASCII 字符的场景有 2~5 倍的性能提升
每个优化的提升幅度都不小。说白了就是"人工智能":有多少人工(写 if 分支),就有多少智能(性能提升)。
案例二:时区处理特化
你的数据使用什么时区?需不需要考虑一些古老时区的奇异规则?
直到最近我才知道,历史上有些地方的时区偏移量不仅不是整小时,也不是整分钟,甚至不是整秒。想想也合理:在 UTC 或现代计时方式推行之前,各地用地方时,和伦敦的经度差会导致各种"奇怪"的偏移量。
如果你的代码不需要处理这些古老时区,甚至只需要处理 UTC,那么很多操作就可以大大简化。
例如 date_trunc 函数(给定一个时间戳,将精度截取到分钟、小时、秒等)的优化(DataFusion#16859):
原实现: 对每个输入时间戳都老老实实地按照严谨的、尊重各种奇异时区的方式转换和规整化,然后截取。这很慢,也无法向量化执行,因为底层用的 chrono 库的 API 都是单条处理的。
优化方法: 先检查输入条件:
- 时区是否是 UTC(或没有时区)
- 要截取的单位是否是"年/月"(这两个单位比较麻烦,因为长度不固定)
如果截取的是"小时/分钟/秒"这类单位,那么在计算机支持的时间范围内,这些单位的换算关系是恒定的。比如一分钟永远是 60 秒,不管在哪个时区、哪个时间戳。
关键代码:
rust
// fast path for fine granularity
// For modern timezones, it's correct to truncate "minute" in this way.
// Both datafusion and arrow are ignoring historical timezone's non-minute granularity
// bias (e.g., Asia/Kathmandu before 1919 is UTC+05:41:16).
// In UTC, "hour" and "day" have uniform durations and can be truncated with simple arithmetic
if granularity.is_fine_granularity()
|| (parsed_tz.is_none() && granularity.is_fine_granularity_utc())
{
let result = general_date_trunc_array_fine_granularity(
T::UNIT,
array,
granularity,
tz_opt.clone(),
)?;
return Ok(ColumnarValue::Array(result));
}通过对输入做更多假设和预检查,为常见场景写 fast path,整体性能会有明显提升。这个 PR 在一些场景提升了 7 倍的性能。
关于 date_trunc 有个更有趣的后续 PR DataFusion#18356,展现了一些我们在第三部分将谈到的零散优化技巧。
案例三:数据范围特化
你的数据是一个 UUID 还是一个 u128?还是一个比较小的 u8 或 u16?
如果数字范围很小,可以直接用数组模拟 map 的行为,完全避免哈希计算。
特化的代价
当然,特化不能过度。这里有个真实但有点"开玩笑"的例子:
有一次为了做静态分发,我们在 GreptimeDB 写了一个宏,根据输入的数据类型做 match,分发到具体类型的计算函数。这个宏嵌套了三层,每层十几个类型。编译没问题,但展开后有 1000 多个 match arm。
结果?运行时能把 Rust 程序跑出"段错误"。如果默认栈大小没调大,这 1000 个分支会直接把栈打爆。
rust
macro_rules! define_eval {
($O: ident) => {
paste! {
fn [<eval_ $O>](columns: &[VectorRef]) -> Result<VectorRef> {
with_match_primitive_type_id!(columns[0].data_type().logical_type_id(), |$S| {
with_match_primitive_type_id!(columns[1].data_type().logical_type_id(), |$T| {
with_match_primitive_type_id!(columns[2].data_type().logical_type_id(), |$R| {
// clip(a, min, max) is equals to min(max(a, min), max)
let col: VectorRef = Arc::new(scalar_binary_op::<
<$S as LogicalPrimitiveType>::Wrapper,
<$T as LogicalPrimitiveType>::Wrapper,
$O,
_,
....(过度特化的例子)
所以:可以适当做特化,但不要过度;不要什么都无脑特化,不一定有收益。
编译时间的代价
除了手动特化,我们也常通过泛型参数,用 Rust 的类型系统写单态化代码,让编译器帮我们特化。
但这会带来另一个问题:编译时间越来越长。
我追踪了一段时间 DataFusion 的编译时间变化:
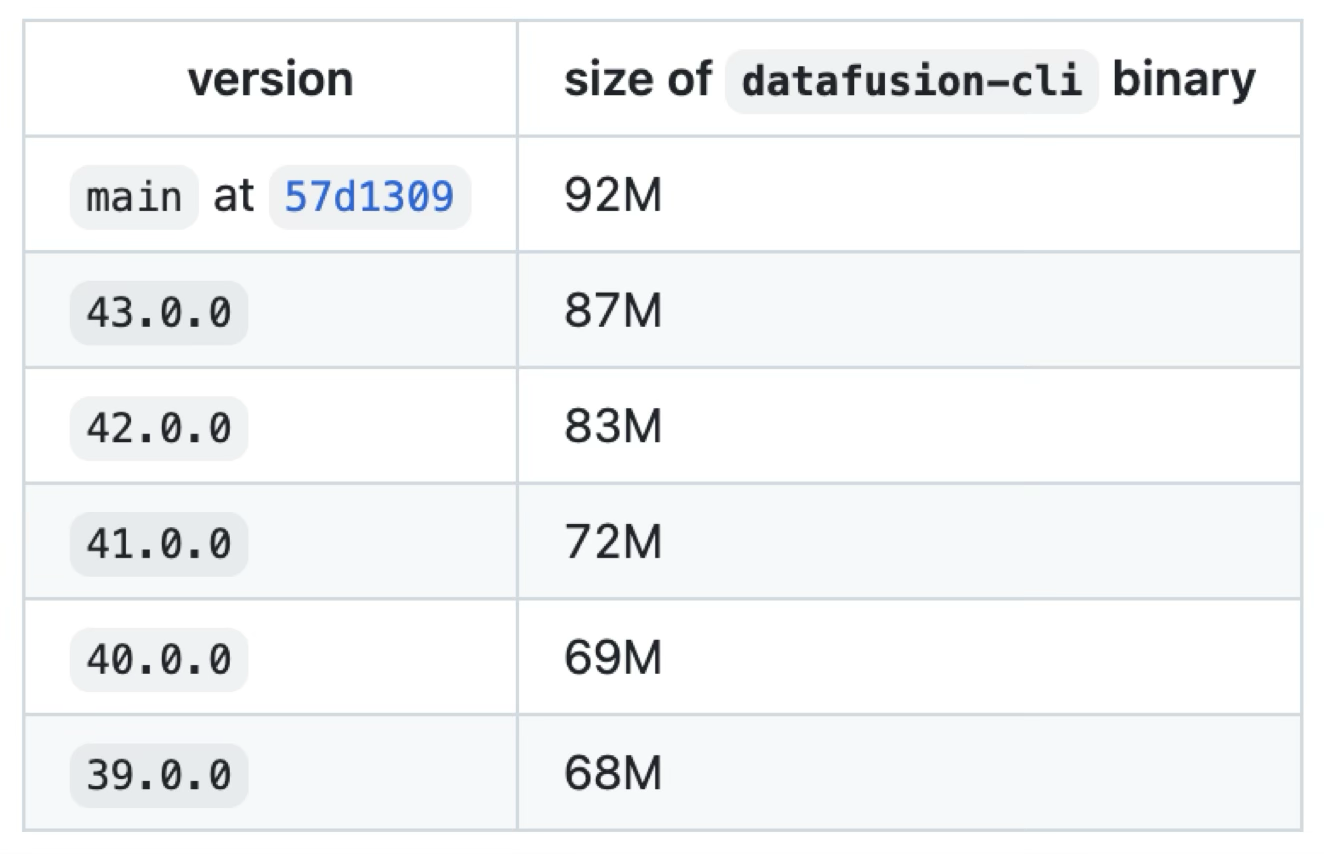
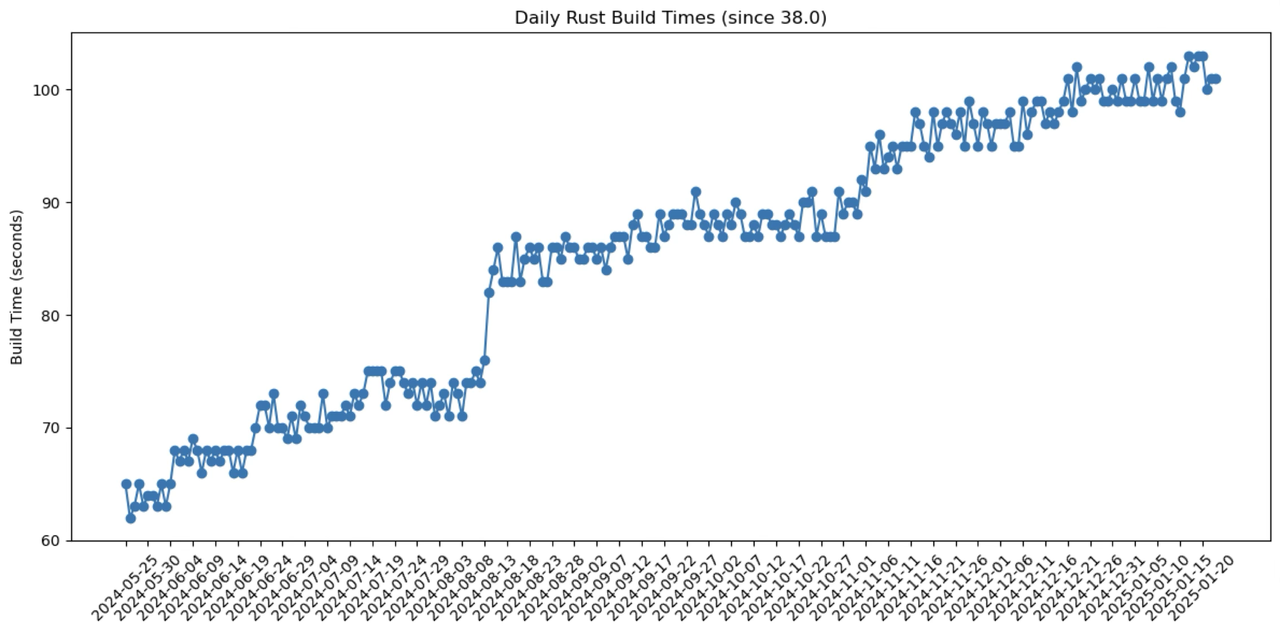
在大约半年时间里,DataFusion 在我机器上的编译时间增加了约 80%,二进制大小从 68M 增长到 92M。
我们还没有确定的结论(欢迎指教),但怀疑是过多的单态化导致的。比如:
- 每个算子、每个类型都会做一次展开
- 标准库的 iterator trait 展开最多
- DataFusion 自己的 tree visitor 结构也会大量展开(因为参数中有闭包,每次使用都会生成新代码)
虽然有这些怀疑,但暂时没有特别好的解决办法。这些都是比较基础的结构,想改不容易,而且改完可能节省了编译开销,却增加了运行时开销。
做个对比:虽然 DataFusion 现在编译已经挺慢(本地要 100 多秒),但在 C++ 项目里这个问题更严重——比如 ClickHouse 编译要半小时,所以也还能接受。
优化三:一些零散的技巧
编译器的局限性
现在的编译器很强大,但还是有很多典型 case 优化不掉。
1. 组合子中的分配
像这样的代码:
rust
// ❌ 不好:每次都会分配
foo.unwrap_or(String::from("empty"));
// ✅ 更好:惰性求值
foo.unwrap_or_else(|| String::from("empty"));在组合子里使用闭包是推荐的,但直接做内存分配可能会被 clippy 警告(or_fun_call 规则)。即使没走到这个分支,也会付出分配的代价。
如果套一个闭包,就能变成 lazy evaluation,只在需要时才分配。
GreptimeDB 的 code style guide 中也专门提到了这一点:
Prefer with_context() over context() when allocation is needed to construct an error.
2. 常量提升
你可能认为编译器会把"常量分配"提升到循环外,或者把 iterator 展开成 for 循环,但实操下来并不总是如此。
DataFusion#12305 就是一个例子:把 iterator 中的一个 format! 调用提到外面,端到端延迟就降低了不少。

减少内存分配
除了前面提到的场景,其他地方也要尽可能减少各种 allocation。
3. 复用堆对象
最直接的方法是复用结构。Rust 没有 GC,大家通常觉得"没有 GC = 好",但真用起来会发现:当一个变量不停分配和释放时,你会希望语言自带对象池。
Rust 这边没有这类机制,得自己做——尽可能复用堆上的对象。
例如这个例子(DataFusion#16878):

之前每次调用都会创建新 String 并返回;改成复用同一个 String,每次传入并在原地修改。这个简单改动在 microbenchmark 中能降低约 15% 的延迟。
4. prost 的教训
还有一个让我印象深刻的例子:prost 这个 Rust 的 protobuf 库。
Rust 标榜"零成本抽象",但库不一定做到。根据我们的测试,prost 可能比 Go 的 gogo/protobuf 慢 8 倍以上。
原因是 prost 就像前面的反面示例一样:哪里需要就直接 new,或者直接生成 String、Vector。你在 proto 里怎么写,它就照原样翻译成 Rust 代码,不做任何优化。
我们当时发现这个问题后做了些优化(GreptimeDB#3425),最后发现整个系统端到端的吞吐,仅仅优化协议序列化这一步(修改 prost 生成的代码),就能提升 40% 以上。
编者注:这个优化我们有一篇精彩的文章,推荐一读:Rust 解码 Protobuf 数据比 Go 慢五倍?记一次性能调优之旅
注意"糖果"的代价
.collect()、.clone() 或 .to_string() 可能代价很高。
一些例子:
- Speed up chr UDF (~4x faster) #14700
- Improve substr() performance by avoiding using owned string #13688
通常的做法是:
- 原来可能先
collect()成Vector,再拿去处理 - 或者每一步都
to_string()来绕过生命周期问题
稍微改一下,比如直接往最终容器里塞数据,而不是先做中间变量再放进容器,在很多场景下都能有不小的提升。
预分配容量
另外,对于 Vector 这类容器,有时我们可以提前知道它会有多大——从输入长度可以推导输出长度。
我 review 代码时看到 Vec::new() 都会多看一眼,想想能不能改成 Vec::with_capacity()。这类改动基本是"白捡"的性能提升,虽然不一定每次都有效,但只要不做得太离谱,也很少有坏处。
我用 ast-grep 扫了一下 DataFusion,发现有 271 处"直接创建 Vector 然后 push"的模式:
bash
~/repo/arrow-datafusion on main *13 !2 ?10
> ast-grep scan -r unsized-vec.yml --report-style short | wc -l
271这 271 个地方中有不少 low-hanging fruit,可以直接带来性能提升。大家可以在自己项目里试试类似的扫描。
Benchmark 的重要性
讲了这么多优化技巧,但别忘了最重要的一点:性能要靠测。
Benchmark 归根结底是数字游戏,但它有很多好处:
- 量化认知:你能知道程序在什么场景下能跑多快,心里有数
- 有效沟通:和别人交流时有具体数字可聊。这一步是不是优化?优化了多少?有数字就好量化
- 持续驱动:如果没有数字,你可能都不知道自己做得对不对,整体优化节奏就会放缓
Benchmark 还要"好跑"。如果把门槛降低,新人刚来项目还不知道能做什么,可以先跑跑 Benchmark,说不定就能发现新的优化点。你也可以方便地回测性能是否退化。
DataFusion 的 Benchmark
DataFusion 有两类现成的 Benchmark:
- Micro-benchmark:使用 criterion,针对具体函数或模块
- 端到端测试:包括 ClickBench、TPC-H 等
这些都有封装好的脚本:
bash
# 创建数据
./benchmarks/bench.sh data
# 运行 TPCH benchmark
./benchmarks/bench.sh run tpch
# 对比两个分支
git checkout mybranch
./benchmarks/bench.sh run tpch
./bench.sh compare main mybranch一键能跑,包括数据生成、指定 case、结果对比等。欢迎大家尝试,说不定就能发现新的优化机会。
超越基础优化
最后强调一点:基础优化应该是第二步。第一步,或者说任何时候,都应该先考虑"这个地方是不是要做这件事"。然后才是"如果要做,怎么做得更快"。
常言道:"过早优化是万恶之源"(premature optimization is the root of all evil)。先找一条更短的路,永远比研究怎么走得更快要好(当然我不是在讨论健康)。
优化即限制
还有一点需要强调:绝大多数时候,优化 = 加限制。
限制越多,性能可能越好(比如前面各种特化)。但代价是:
- 限制越多,对人脑负担越大——要记住的东西更多
- 很多本来能写的代码可能就写不出来了
在开发体验方面,我觉得最难受的前几名之一就是 Arrow 的类型系统。接触这些之前我基本不怎么用 downcast,但接触之后天天写 downcast。
我扫了一下,DataFusion 里大概有 500 多处 downcast:
bash
~/repo/arrow-datafusion on main *13 !2 ?10
> rg ".downcast_ref::" | wc -l
539作为静态类型语言,我第一次看到时会想:怎么会变成这样?
更多限制也会带来更多隐藏的知识(tribal knowledge)。比如两个 API 都能干同一件事,但其中一个就是比另一个快,因为它做了额外优化。这类"部落知识"很难传播和维护。
这里有两个 DataFusion 的例子:
- Optimize iszero function (3-5x faster) #12881
- Speed up struct and named_struct using invoke_with_args #14276
只是简单换了个 API,做的逻辑完全不变,就能带来很大提升。但这种知识需要熟悉代码库才能掌握。
总结
今天分享了一些在 DataFusion 和 GreptimeDB 中实践的基础优化技巧:
善用
HashMapHashMap本身就是优化- 考虑替换实现(如
ahashmap) - 必要时基于
HashTable深度定制
代码特化
- 针对 ASCII 字符串优化
- 针对特定时区优化
- 针对数据范围优化
- 但不要过度特化
零散技巧
- 注意闭包的惰性求值
- 复用堆对象
- 减少不必要的分配
- 预分配容器容量
Benchmark 驱动
- 用数字说话
- 降低运行门槛
- 持续监控性能
更高层面
- 逻辑优化优先于性能优化
- 优化即限制,需要权衡
这些都是"基础"的东西——不是因为它们简单,而是因为它们适用范围广、收益明确、风险可控。在追求高性能的同时,也要考虑代码的可维护性和开发体验。
感谢大家!如果对 DataFusion 或性能优化感兴趣,欢迎参与社区讨论。
相关链接
- Apache DataFusion: https://github.com/apache/datafusion
- GreptimeDB: https://github.com/GreptimeTeam/greptimedb
- 文中提到的 PRs 和 Issues 都已附链接
注:本文基于 Apache CoC Asia 2025 的演讲整理而成

