本页内容
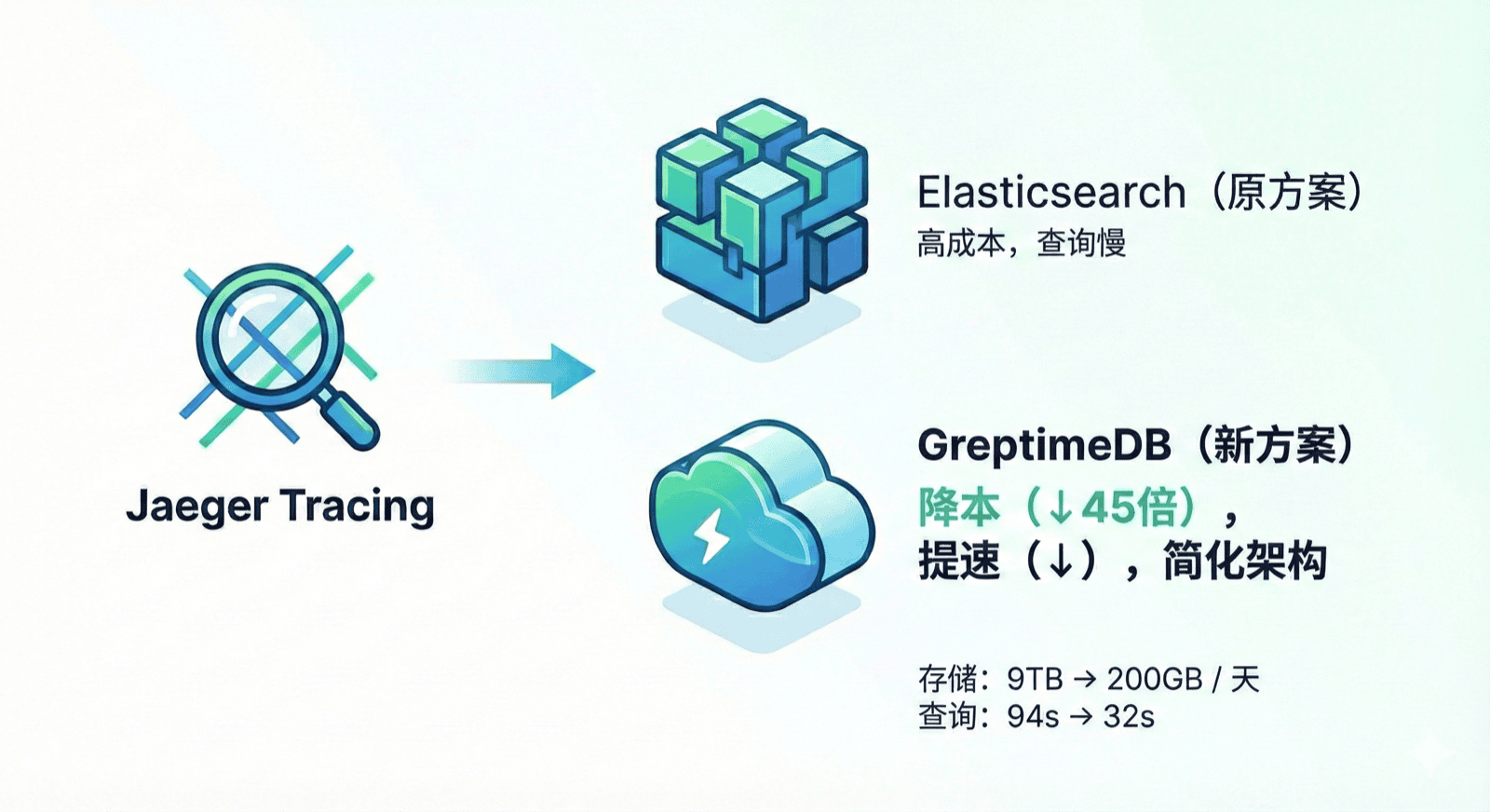
近期,某出海物流与电商仓储公司在分布式链路追踪场景中,使用 GreptimeDB 替换 Elasticsearch 作为 Jaeger 的存储后端。替换后存储成本降低 45 倍,查询耗时从 94 秒降到 32 秒,同时计算资源缩减一半以上。本文将介绍这次迁移的背景、实践过程与最终收益。
背景
该公司的业务系统采用微服务架构,通过 Jaeger 进行分布式链路追踪(Distributed Tracing)。随着业务规模扩大,Trace 数据量持续增长——高峰期每秒写入量达到 80,000 条,部分消费类服务的数据量甚至更高。按当前采样率,3 天的 Trace 数据量约 130 亿行;如果全量采集,预估每天将产生约 400 亿行数据。
原有的链路追踪架构如下:
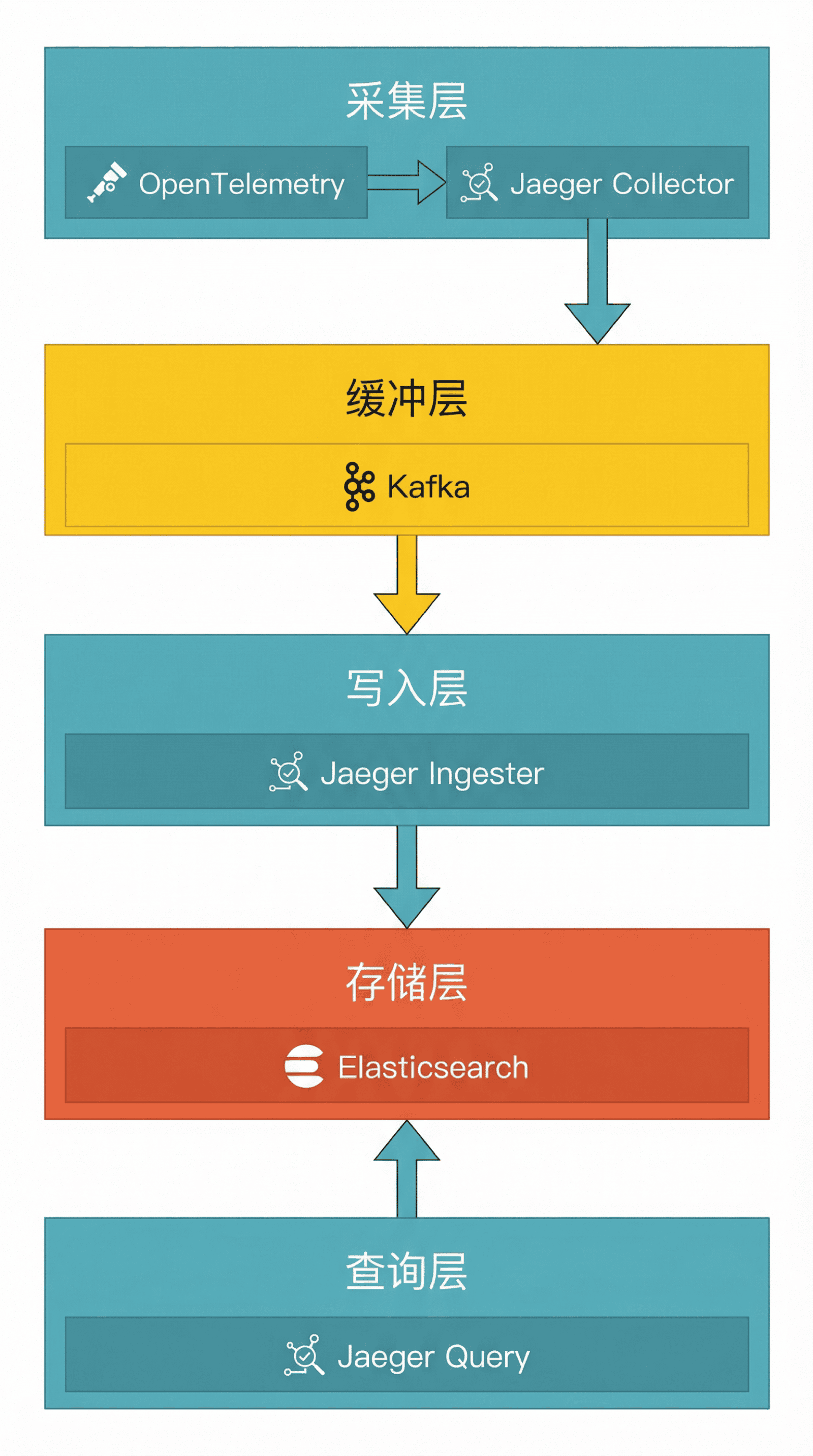
数据流经 OpenTelemetry SDK → Jaeger Collector → Kafka → Jaeger Ingester → Elasticsearch,最后由 Jaeger Query 提供查询服务。
这套架构有一个关键点:中间加了一层 Kafka 做缓冲。这是因为 ES 的写入性能有限,高峰期容易成为瓶颈,需要 Kafka 来削峰填谷、缓解写入压力。
这套架构在初期运行良好,但随着业务扩展,ES 暴露出明显的性能和成本问题。
原方案的困境
该公司的 ES 集群配置为 3 个节点,单节点规格 16C 64G,配备 4T 本地存储,总计 48C/192G/12T。Jaeger 默认按 jaeger-<service-name>-YYYY.MM.DD 格式为每个服务每天生成独立索引:
jaeger-order-service-2025.10.28
jaeger-payment-service-2025.10.28
jaeger-inventory-service-2025.10.28
...这种存储方式带来了几个显著问题:
数据膨胀严重。ES 的多服务索引分散存储,加上倒排索引、doc_values、_source 等开销,存储空间消耗很大。ES 控制台显示文档数高达 1000 亿,但实际有效数据远低于此。3 台机器的本地存储,一天就消耗 9T。
查询性能不稳定。ES 查询性能强依赖内存缓存:命中缓存时约 10 秒,冷数据查询则飙升到 1.5 分钟以上。排查线上问题时,工程师经常需要等待漫长的查询返回。
数据保留受限于本地磁盘。12T 的本地存储很快写满,不得不频繁清理历史数据。当需要回溯分析更早的问题时,数据可能已经被清理掉了。
架构复杂度高。为了缓解 ES 的写入压力,不得不引入 Kafka 做缓冲,增加了运维成本和故障点。
为什么选择 GreptimeDB
在评估多个方案后,该公司选择了 GreptimeDB,主要考量包括:
存算分离架构
GreptimeDB 采用存算分离架构(Decoupled Compute and Storage),数据持久化在对象存储上,计算节点无状态、易扩展。这种架构适合 Trace 这类数据量大、查询相对低频的场景:历史数据放对象存储,计算侧按需扩容即可。
更重要的是,数据保留时长不再受限于本地磁盘容量。对象存储容量几乎不受单集群磁盘限制,可以按需保留更长时间的 Trace 数据,便于回溯分析历史问题。
客户表示:"放对象存储上,保存时长也可以非常长。"
列式存储与轻量索引
GreptimeDB 采用列式存储,配合跳数索引(Skipping Index)而不是全量倒排索引。这种设计在 Trace 场景下有明显优势:
- 存储空间小:列式存储压缩率高,跳数索引只记录数据块的统计信息,索引体积远小于倒排索引
- 写入吞吐高:无需维护复杂的倒排索引结构,写入开销更低
- 查询更稳定:对缓存预热的依赖更小,冷热数据查询耗时更接近
当然,这种设计的取舍是:对"精确命中、强过滤"的点查场景,倒排索引往往更占优势。但在 Trace 场景里,查询通常是"时间范围 + 条件过滤",而不是全文检索;用轻量索引配合列式扫描,整体更划算。
Jaeger 原生兼容
GreptimeDB 提供 Jaeger 查询接口兼容,Jaeger UI 可以直接对接 GreptimeDB,无需修改前端查询逻辑。这大幅降低了迁移成本——工程师继续使用 Jaeger UI 即可。
统一的数据模型
与 ES 按服务和日期分散索引不同,GreptimeDB 用统一表结构存储所有 Trace 数据。一张 opentelemetry_traces 表即可承载所有服务的链路数据,减少重复存储带来的膨胀。
新架构设计
迁移后的链路追踪架构如下:
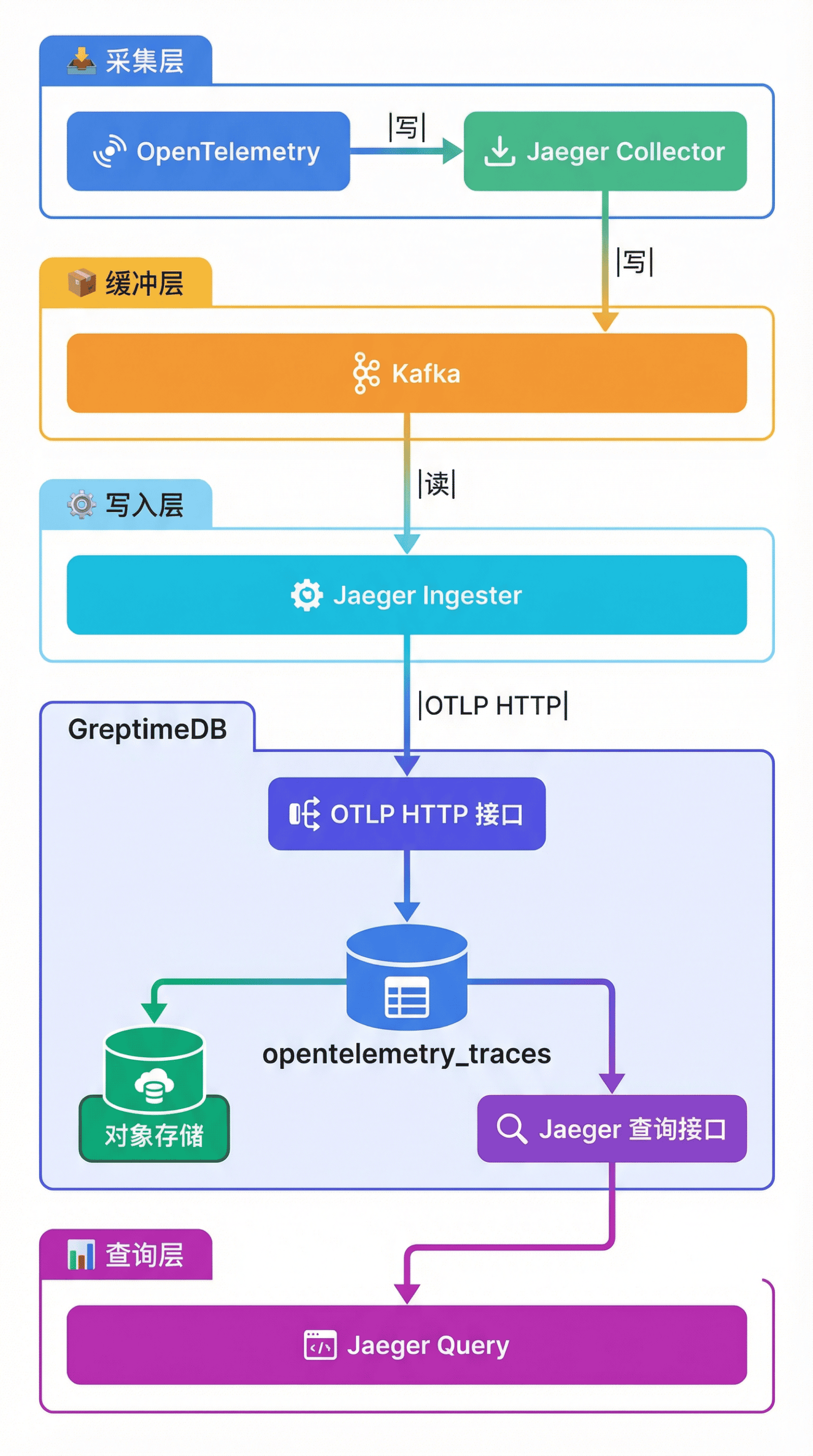
核心变化:
- 存储后端替换:Jaeger Ingester 通过 OTLP HTTP 协议将 Trace 数据写入 GreptimeDB,替代原来的 ES
- 统一表存储:所有服务的 Trace 数据存储在
opentelemetry_traces单表中 - 对象存储持久化:数据落盘到对象存储(如阿里云 OSS),实现存算分离
- Jaeger Query 直接对接:GreptimeDB 兼容 Jaeger 查询接口,Jaeger Query 直接查询 GreptimeDB
目前该公司保留了 Kafka 缓冲层,主要是为了平滑迁移。由于 GreptimeDB 的写入吞吐足够高,未来可以移除 Kafka,让 Collector 直接写入 GreptimeDB,进一步简化架构:
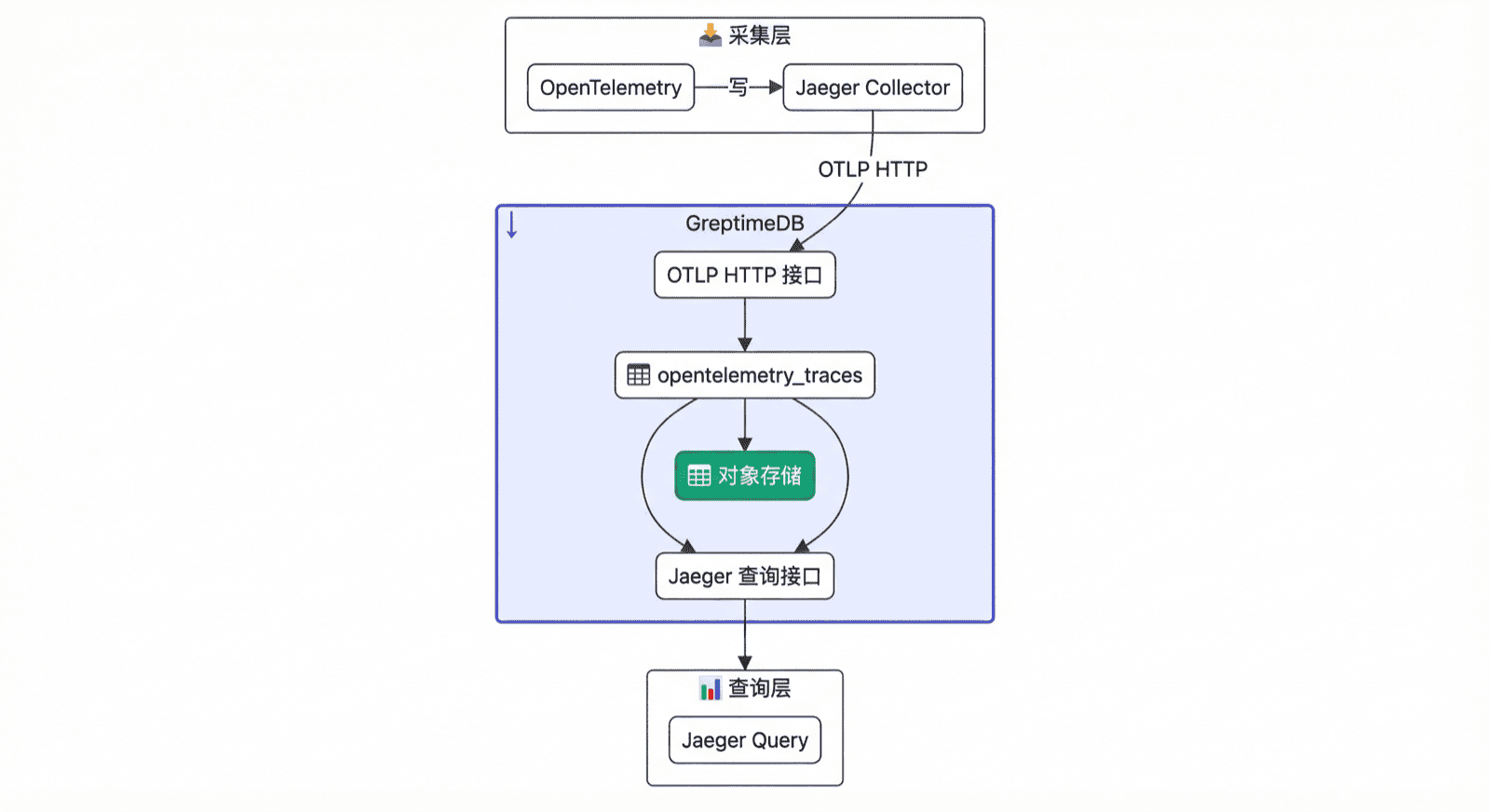
少一个组件意味着:运维成本更低、故障点更少、数据链路更短,整体延迟也更可控。我们还推荐使用 Grafana 的 Jaeger 插件,在性能更好的同时,也可以享受 Grafana 的生态。
迁移亮点:由于 GreptimeDB 兼容 Jaeger 查询接口,Jaeger Query 可以直接切换到 GreptimeDB,工程师无需改变使用习惯。详见 GreptimeDB Jaeger 兼容文档。
部署配置
集群规格
该公司将 GreptimeDB 部署在 Kubernetes 集群中,采用以下节点配置:
| 组件 | 规格 | 数量 |
|---|---|---|
| Metasrv(元信息节点) | 2C 4G | 1 |
| Frontend(前端节点) | 4C 8G | 2 |
| Datanode(数据节点) | 8C 32G + 500G SSD | 2 |
总计算资源约 26C/84G,相比原 ES 集群的 48C/192G,计算资源缩减一半以上。
数据存储在阿里云 OSS(标准存储类型)上,充分利用对象存储的低成本和高可用特性。
查询场景
该公司的 Trace 查询主要有两类场景:
- 按条件筛选链路:查询某个时间范围内、某个接口的链路,通常附加响应时间等过滤条件
- 按 Trace ID 点查:根据具体的 Trace ID(如
99e490ca129d777d05f6ca4716fade8c)查询完整链路详情
效果与收益
经过并行运行验证,GreptimeDB 的表现超出预期。
存储成本大幅下降
| 指标 | Elasticsearch | GreptimeDB | 对比 |
|---|---|---|---|
| 单日存储占用 | ~9,000 GB(9T) | ~200 GB | 降低 45 倍 |
| 3 天数据占用 | ~27,000 GB(27T) | ~600 GB | 降低 45 倍 |
| 存储介质 | 本地 SSD(容量有限) | 对象存储 | 容量不受单机磁盘限制 |
客户表示:"节省 10 倍以上不夸张,况且 OSS 还便宜。"
45 倍的存储降幅主要来自几方面:一是列式存储的压缩率,二是跳数索引相比倒排索引体积更小以及单表替代了多索引配置。130 亿行数据的索引大小仅 136GB,而 ES 的倒排索引开销要大得多。
在存储空间降低的基础上,对象存储的单位成本通常也低于本地 SSD,综合存储成本下降更明显。更重要的是,数据保留周期不再受限于本地磁盘容量——原来 12T 的本地存储很快写满,现在可以根据业务需要保留数周甚至数月的 Trace 数据。
查询性能显著提升
| 场景 | Elasticsearch | GreptimeDB | 对比 |
|---|---|---|---|
| 查询耗时 | ~94 秒(冷数据)/ ~10 秒(热数据) | ~32 秒(更稳定) | 提速近 3 倍 |
GreptimeDB 的查询耗时更稳定。ES 的查询耗时取决于数据是否命中缓存,冷热差异可达 9 倍;而 GreptimeDB 查询冷数据和热数据的耗时更接近,整体可预期性更强。
需要说明的是,具体的查询耗时与数据规模、查询复杂度、软硬件配置等因素密切相关。该客户采用的是成本优先的集群配置(26C/84G),如果增加计算资源或优化缓存配置,查询性能还有进一步提升的空间。
客户表示:"相同条件还是 GreptimeDB 快。"
计算资源优化
| 指标 | Elasticsearch | GreptimeDB | 对比 |
|---|---|---|---|
| CPU | 48C | ~26C | 节省约 46% |
| 内存 | 192G | ~84G | 节省约 56% |
存算分离架构下,计算资源可以按需配置:数据放对象存储,计算节点主要负责写入与查询处理,不需要为本地磁盘预留同等规模的资源。
业务价值提升
由于存储成本大幅降低,该公司计划从"采样采集"逐步转向"全量采集"。
采样采集虽然能控制成本,但排查问题时可能丢失关键链路信息。全量采集能保证问题排查时有更完整的数据可查,提升可观测性的覆盖度和定位效率。
客户表示:"存储和计算成本降低,其实可以调高采样率,对业务更有帮助。"
按照目前的规模,全量采集后每天的数据量预计达到 400 亿行。得益于 GreptimeDB 的压缩与对象存储的成本优势,这一目标在成本上变得可行。
经验总结
迁移周期
整个迁移过程大约一周完成,主要工作包括:部署 GreptimeDB 集群、配置 Jaeger Ingester 对接、验证数据写入和查询功能。迁移本身并不复杂,后续的时间主要花在性能调优上。
数据模型差异
ES 和 GreptimeDB 的数据模型有本质区别:ES 使用多索引分散存储(jaeger-<service>-YYYY.MM.DD),GreptimeDB 使用单表统一存储。
迁移时需要理解这个差异:ES 显示的"文档数"可能因统计口径不同而偏高,而 GreptimeDB 的行数更接近实际写入量。该客户在 ES 中看到 1000 亿文档,但 GreptimeDB 中 3 天数据约 130 亿行——这更符合他们对实际数据规模的预期。
查询调优与缓存配置
迁移过程中,团队花了较多时间做查询调优,重点在缓存配置。GreptimeDB 的查询性能与缓存策略相关,需要结合实际查询模式调整缓存参数。
建议在迁移初期预留足够的调优时间,通过监控慢查询和缓存命中率逐步优化配置。详细的缓存调优指南可参考 GreptimeDB 性能调优文档。
未命中 Trace ID 的查询优化
在迁移初期,团队发现按 Trace ID 查询但数据不存在(未命中)时,查询会更慢。这是因为系统需要扫描更多数据块来确认"不存在"。
针对这个问题,GreptimeDB 团队在即将发布的 v1.0 RC1 版本中做了优化,显著提升了未命中场景的查询性能。建议关注新版本发布。
Jaeger UI 跨域问题
如果使用 Jaeger UI 本地模式对接 GreptimeDB,可能会遇到跨域访问问题。解决方法是在 Jaeger UI 的 webpack/vite 配置中添加 allowedHosts: true:
javascript
// jaeger-ui 服务器配置
server: {
proxy: {
'/api': proxyConfig,
'/analytics': proxyConfig,
'/serviceedges': proxyConfig,
'/qualitymetrics-v2': proxyConfig,
},
allowedHosts: true, // 添加此行解决跨域问题
},这个配置允许 Jaeger UI 接受来自任意主机的请求,解决跨域限制。
索引大小估算
GreptimeDB 会为 Trace 数据建立索引。该客户 130 亿行数据的索引大小约为 136GB,相比 ES 的索引开销要小很多。
可以通过系统表查看表的行数:
sql
SELECT table_rows
FROM information_schema.tables
WHERE table_name = 'opentelemetry_traces';查询时间范围
由于查询性能提升且更加稳定,工程师在排查问题时可以把时间范围拉得更大。原来在 ES 上查冷数据要等 1.5 分钟,现在可以更从容地查询 1 小时甚至更长时间范围的链路。
总结
该公司使用 GreptimeDB 替换 Elasticsearch 存储 Jaeger Trace 数据,取得了明显的降本增效效果:
- 存储成本降低 45 倍:列式存储 + 跳数索引 + 对象存储,缓解数据膨胀问题
- 数据保留不再受限:对象存储不受单机磁盘容量限制,可按需延长历史数据保留周期
- 查询性能提升近 3 倍:查询耗时从 94 秒降到 32 秒,且冷热数据差异更小
- 计算资源缩减一半以上:存算分离架构下按需配置计算资源
- 架构可进一步简化:GreptimeDB 写入吞吐足够高,未来可移除 Kafka 缓冲层
- 迁移成本低:一周完成迁移,Jaeger Query 可直接切换
对于有类似 Trace 存储需求的团队,GreptimeDB 的存算分离架构和压缩能力值得评估。尤其是数据量大、查询相对低频的场景,用对象存储作为数据底座,通常能显著降低总体拥有成本(TCO)。
感谢该客户对 GreptimeDB 的信任与配合,在迁移过程中提供了宝贵反馈,帮助我们持续改进产品。

