
本页内容
前言
在《什么是可观测性 2.0 ?什么是可观测性 2.0 原生数据库?》一文中,我们介绍了宽事件的概念。我们提出以“宽事件”(wide events)作为统一且具备丰富上下文的数据基础,旨在解决传统问题,如数据孤岛、预聚合、非结构化日志以及数据冗余等,进而满足现代系统日益增长的复杂性和灵活分析需求。
本文译自《Observability wide events 101》,作者为 Cloudflare 的可观测性工程师。文章详细阐述了宽事件的概念及应用,解析了宽事件与分布式追踪和 OpenTelemetry 的关联,并澄清了可观测性领域的一些常见误解。
什么是宽事件(Wide Events)
实际上,“宽事件”(Wide Events)的概念非常简单:在每次请求经过服务节点时,仅生成一个包含丰富上下文信息的结构化事件或日志。就是如此直截了当地操作——无需被各类流行术语所误导。
假设正在构建一个博客平台,该平台允许用户保存文章。POST /articles API 的简化流程如下:
- 用户借助浏览器发起请求;
- 请求抵达
gateway,此节点负责进行鉴权操作并编排下游服务; gateway调用articles服务,该服务负责将文章写入数据库并进行缓存;gateway调用notifications服务,该服务会给博客的所有订阅者发送邮件;gateway调用analytics服务,该服务会将消息发送至队列,用于产品分析。
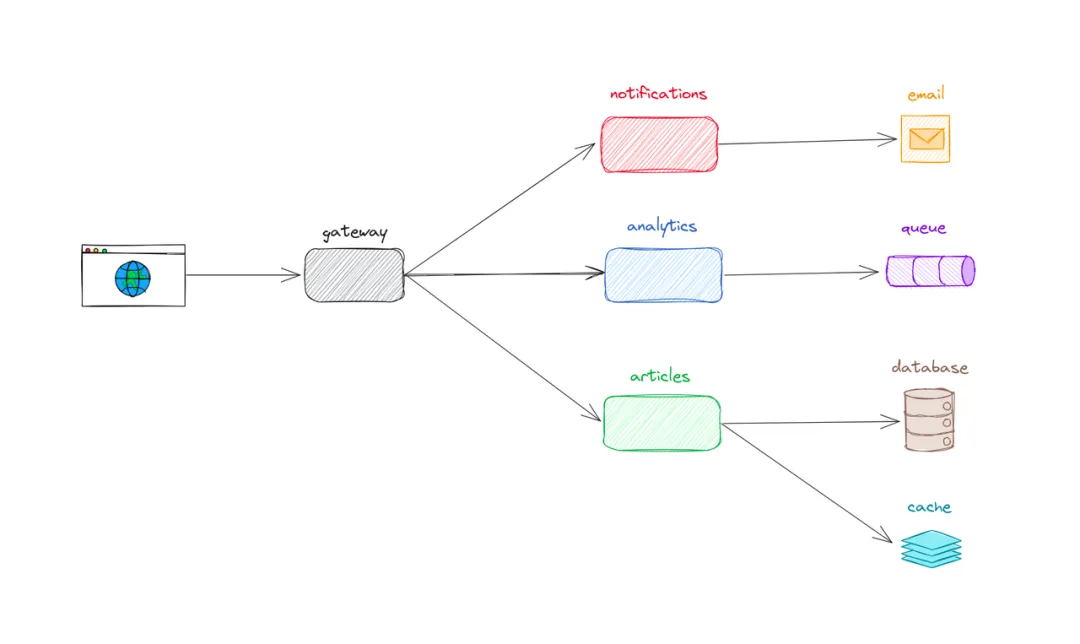
简而言之,这些服务——从浏览器、数据库到队列——每个都应该为每个请求发出一个包含任意多字段的结构化宽事件(wide events)。所有这些事件需通过一个请求 ID 进行关联,以便能够把所有相关事件串联起来。
为什么要用宽事件?
以 articles 服务为例,这类事件应当记录业务逻辑相关的各类细节,比如用户、订阅、保存的文章、响应状态码等等,例如:
json
{
"method": "POST",
"path": "/articles",
"service": "articles",
"outcome": "ok",
"status_code": 201,
"duration": 268,
"requestId": "8bfdf7ecdd485694",
"timestamp":"2024-09-08 06:14:05.680",
"message": "Article created",
"commit_hash": "690de31f245eb4f2160643e0dbb5304179a1cdd3",
"user": {
"id": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"activated": true,
"subscription": {
"id": "1aeb233c-1572-4f54-bd10-837c7d34b2d3",
"trial": true,
"plan": "free",
"expiration": "2024-09-16 14:16:37.980",
"created": "2024-08-16 14:16:37.980",
"updated": "2024-08-16 14:16:37.980"
},
"created": "2024-08-16 14:16:37.980",
"updated": "2024-08-16 14:16:37.980"
},
"article": {
"id": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"title": "Test Blog Post",
"ownerId": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"published": false,
"created": "2024-09-08 06:14:05.460",
"updated": "2024-09-08 06:14:05.460"
},
"db": {
"query": "INSERT INTO articles (id, title, content, owner_id, published, created, updated) VALUES ($1, $2, $3, $4, $5, $6, $7);",
"parameters": {
"$1": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"$2": "Test Blog Post",
"$3": "******",
"$4": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"$5": false,
"$6": "2024-09-08 06:14:05.460",
"$7": "2024-09-08 06:14:05.460"
}
},
"cache": {
"operation": "write",
"key": "f8d4d21c-f1fd-48b9-a4ce-285c263170cc",
"value": "{\"article\":{\"id\":\"f8d4d21c-f1fd-48b9-a4ce-285c263170cc\",\"title\":\"Test Blog Post\"..."
},
"headers": {
"accept-encoding": "gzip, br",
"cf-connecting-ip": "*****",
"connection": "Keep-Alive",
"content-length": "1963",
"content-type": "application/json",
"host": "website.com",
"url": "https://website.com/articles",
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36",
"Authorization": "********",
"x-forwarded-proto": "https",
"x-real-ip": "******"
}
}一眼就能看出来:一名免费试用将于 9 月 16 日到期的用户发了一篇文章,服务以 201 状态码响应,耗时 268ms 响应。
宽事件的特点如下:
- 高基数:每个字段都可以有无限多的唯一值,比如用户 ID、会话 ID、交易等。每天可能有几十亿条这样的事件;
- 高维度:宽事件天然就是字段多,维度多,以便深度洞察;
- 上下文丰富:每一个字段都应该带有丰富的上下文,无论是请求头、基础架构细节还是业务逻辑数据。
日志与指标的局限性
宽事件可以回答传统日志和指标根本无法解答的问题。想象一下,如果我们在 articles 服务中只用常规日志和指标:
plaintext
2024-09-08 06:14:05.280 Received POST /articles request
2024-09-08 06:14:05.298 Saving article: f8d4d21c-f1fd-48b9-a4ce-285c263170cc
2024-09-08 06:14:05.449 Article saved: f8d4d21c-f1fd-48b9-a4ce-285c263170cc
2024-09-08 06:14:05.451 Response time: 254ms
2024-09-08 06:14:05.460 Successful request: 201此外,还需结合一些指标,如请求耗时、创建的文章数量以及失败次数等进行分析。
当前,有一位用户发邮件反馈,每次发布新文章后,都无法在网站上看到该文章,同时还附上了相关视频。另外,还有 67 位用户也给出了类似反馈。从日志来看,一切运行正常,文章也确实已成功写入数据库,指标图上亦未显示异常。
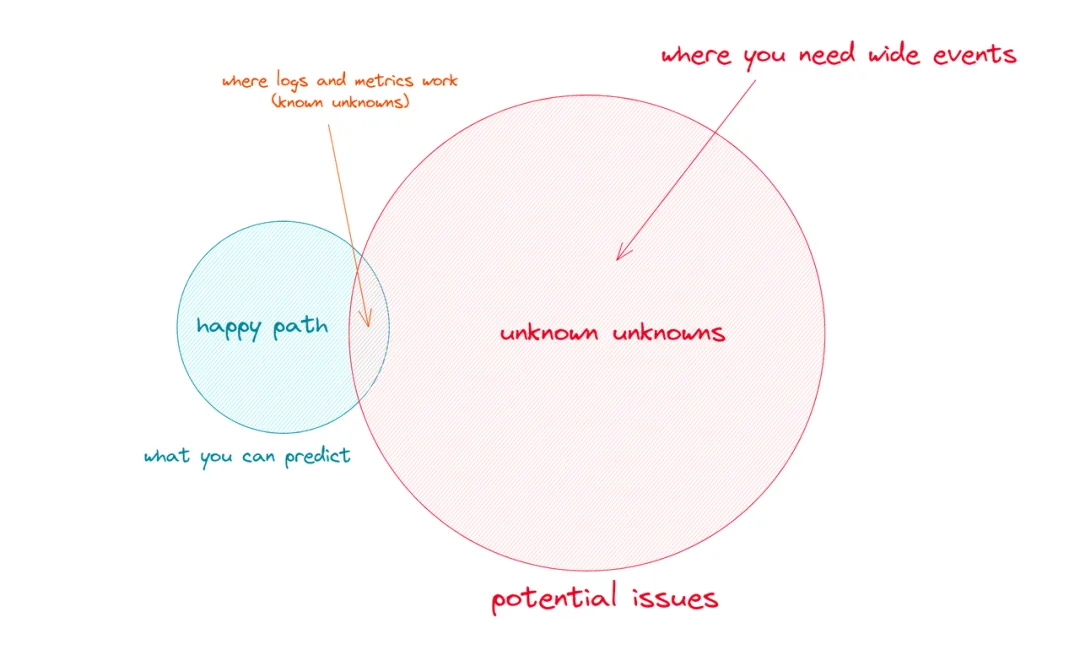
这便是所谓的**“未知的未知”(unknown unknowns)**。
日志和指标有助于捕捉**“已知的未知”(known unknowns)**,即开发过程中能够预想到的错误,例如请求缓慢、报错、数据库故障或其他明显的边界情况。
然而,当系统上线并面对真实用户的各种行为时,就会对那些完全无法预料的异常状况束手无策。
工具选型建议
无论采用何种观测工具,均应满足以下条件:
- 任意维度可查询:能够依据任意字段对事件进行过滤与检索;
- 无预聚合:所有事件均以原始数据形式存储,而非采用批量抽样所得数值;
- 查询速度快:理想情况下查询响应时间应达到秒级,最迟也需在 1 分钟内返回结果;
- 价格可承受:观测性工具不应使系统成本过高,可通过采样大幅降低成本。
笔者曾参与过观测性产品的相关工作,实践表明同时满足上述所有要求颇具挑战,但至少应向厂商或自研方案提出这些要求。
如何用 Wide Events 定位和分析异常?
实际上,在之前的宽事件示例中,若仔细查看,便已包含解决“部分用户发文后无法显示”问题的答案。我们可以基于宽事件数据进行几组查询,以下通过 SQL 伪代码进行演示(具体语法与您所使用的工具相关)。
总发文数量
sql
select count()
from events
where method = "POST"
and path = "/articles"
and status_code = 201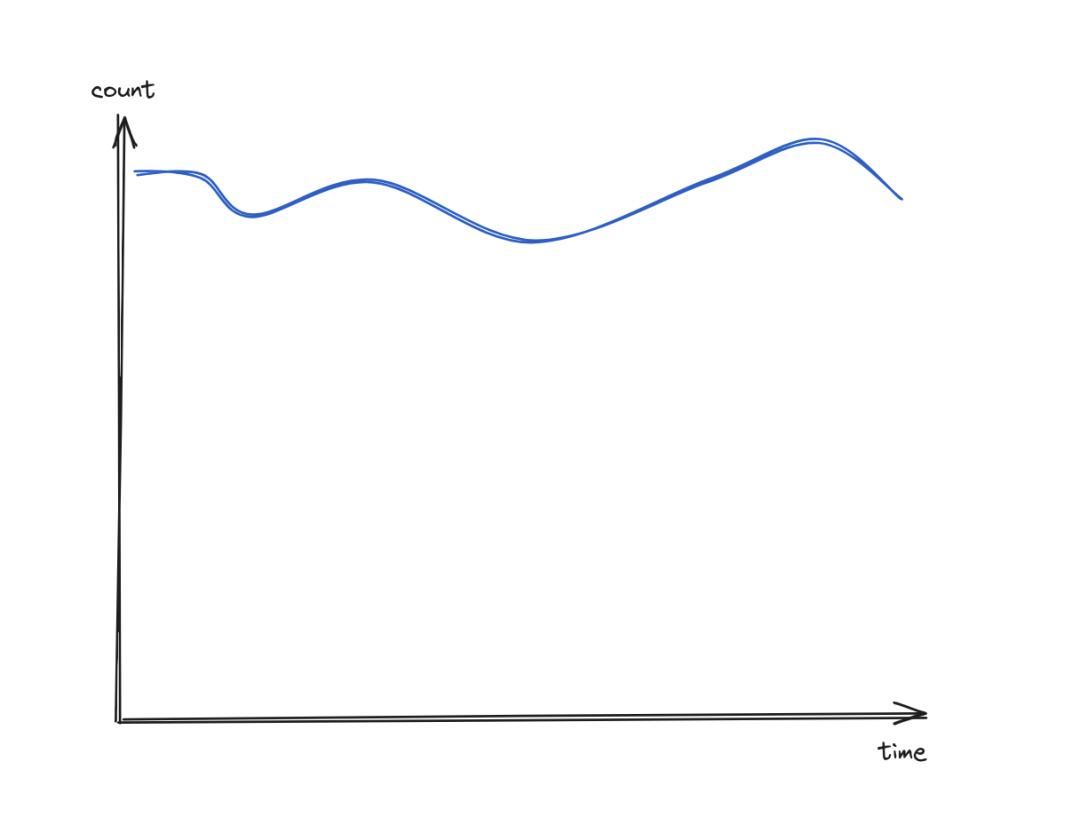
图表显示发文数量总体保持稳定,未出现异常情况。下一步将对这些文章是否确实“已发布”进行分析,按照 article.published 字段进行分组。
按 article.published 分组
sql
select count()
from events
where method = "POST"
and path = "/articles"
and status_code = 201
group by article.published
order by count() desc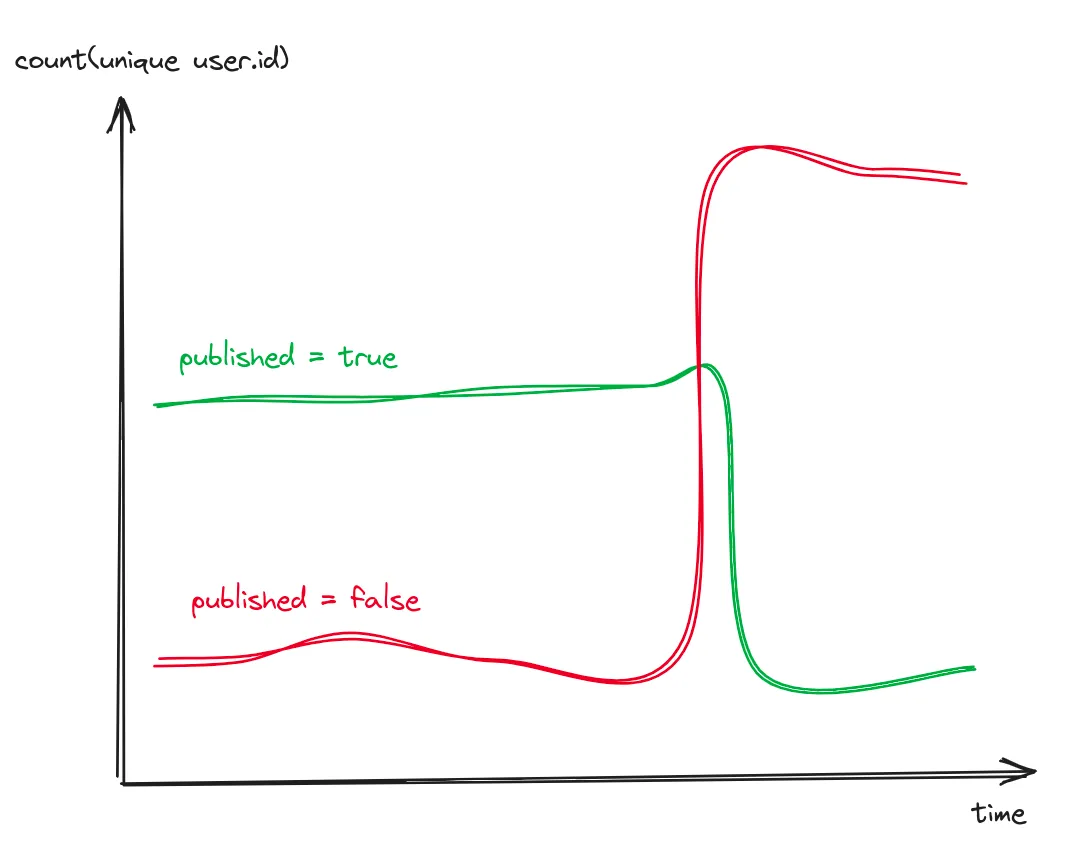
很明显,文章看不到的根因是很多文章 published = false。但为什么?只是个别用户有问题还是普遍现象?
按 user.id 分组未发布文章
sql
select count()
from events
where method = "POST"
and path = "/articles"
and status_code = 201
and article.published = false
group by user.id
order by count() desc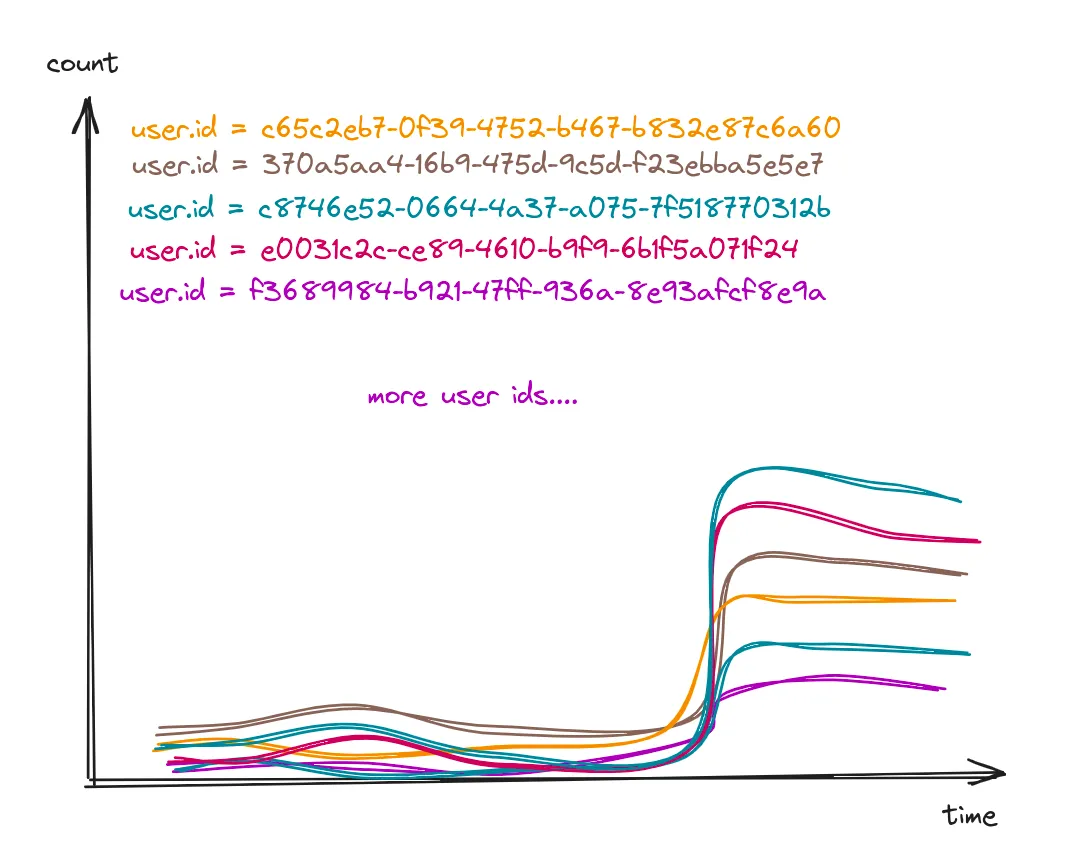
这是多名用户被影响。而到底有多少用户呢?统计唯一用户并按 article.published 分组。
按 article.published 分组的唯一用户数
sql
select count(unique user.id)
from events
where method = "POST"
and path = "/articles"
and status_code = 201
group by article.published起初,只有极少数用户的发文未能发布,而后,突然大部分发文都未能发布。这表明这并非个别特例。那么,这些用户有哪些共同点呢?
过去,凭借结构化日志、海量指标以及仪表盘,或许也能够分析到这一阶段。但在此之后,通常只能凭借主观臆断来查看当天所编写的代码。然而,运用宽事件,只需再提出一个问题,系统就会给出答案。
这些未发布文章的用户是否都处于免费试用期?
唯一用户数,按 article.published 和 user.trial 分组
sql
select count(unique user.id)
from events
where method = "POST"
and path = "/articles"
and status_code = 201
group by article.published, user.trial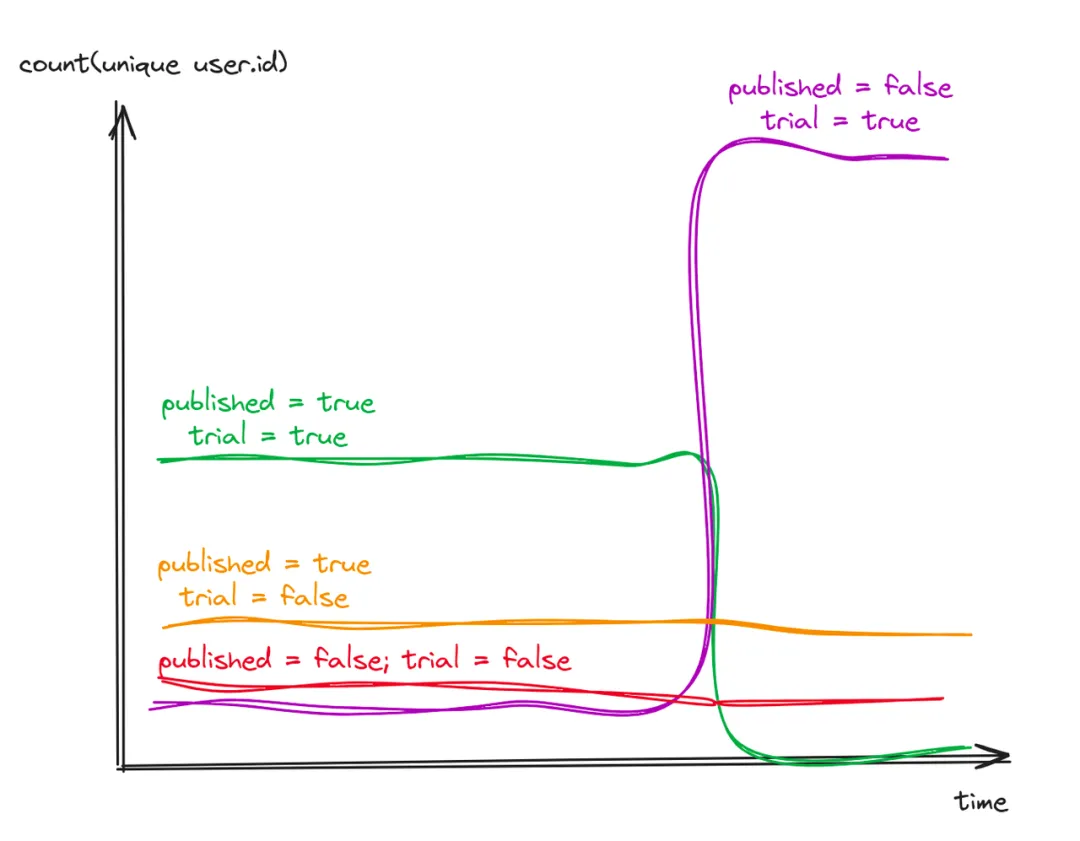
结论清晰明了:仅免费试用用户受到影响,且此类用户数量远超付费用户,因此多数文章处于未发布状态。显然,付费用户未受任何影响。
若你的观测工具支持添加 commit ID/部署等元数据标记,还可一键精确找出引入问题的代码变更。
译者注
上述分析过程本质上属于多维分析的人工探索过程。然而在人工智能时代,实际上只需提供原始的宽事件数据,随后按照自然语言进行提问即可。 例如:“请分析本次变更以来,与变更前的数据相比存在哪些异常情况?按照用户类型、文章状态等维度进行分析,并生成报表。”如有兴趣,可参考 GreptimeDB MCP 的实例。
宽事件的简单实现方式
下面是一个基本实现,以 Node.js 为例:
java
app.post('/articles', async (c) => {
const startTime = Date.now();
// 初始化宽事件
const wideEvent = {
method: 'POST',
path: '/articles',
service: 'articles',
requestId: c.get("requestId"),
headers: c.req.raw.headers,
// 可以选填环境变量
// 保证不要记录敏感信息
env: process.env,
};
try {
const body = await c.req.json();
const { title, content } = body;
const user = database.getUser(c.get("userId"));
wideEvent["user"] = user;
const article = {
id: uuidv4(),
title,
content,
ownerId: user.id,
published: true,
};
const { savedArticle, dbOperation } = await database.saveArticle(article);
wideEvent["article"] = savedArticle;
wideEvent["db"] = dbOperation;
const cacheResponse = await cache.set(article.id, article);
wideEvent["cache"] = cacheResponse;
const response = { message: 'Article created', article };
wideEvent["status_code"] = 201;
wideEvent["message"] = 'Article created';
wideEvent["outcome"] = 'ok';
return c.json(response, 201);
} catch (error) {
wideEvent["outcome"] = 'error';
wideEvent["status_code"] = 500;
wideEvent["message"] = error.message;
return c.json({ error: 'Internal Error' }, 500);
} finally {
const duration = Date.now() - startTime;
wideEvent["duration"] = duration;
wideEvent["timestamp"] = new Date().toISOString();
// 输出宽事件
logger.info(JSON.stringify(wideEvent));
}
});可以进一步借助中间件、辅助方法批量注入字段,或者结合队列确保在请求失败或超时的情况下,宽事件仍能正常输出。
关于 OpenTelemetry
上述简单实现存在一个明显缺陷:如何进行 requestId 的分布式传递?分布式追踪能够自动传播请求 ID、捕获各项时间戳以及服务调用层级,并规范与宽事件相关的语义。从追踪术语的角度而言:
- “宽事件” 即 “span”
- “请求” 即 “trace” 这是因为分布式追踪同样适用于非请求/响应场景(如后台任务、流处理等)。
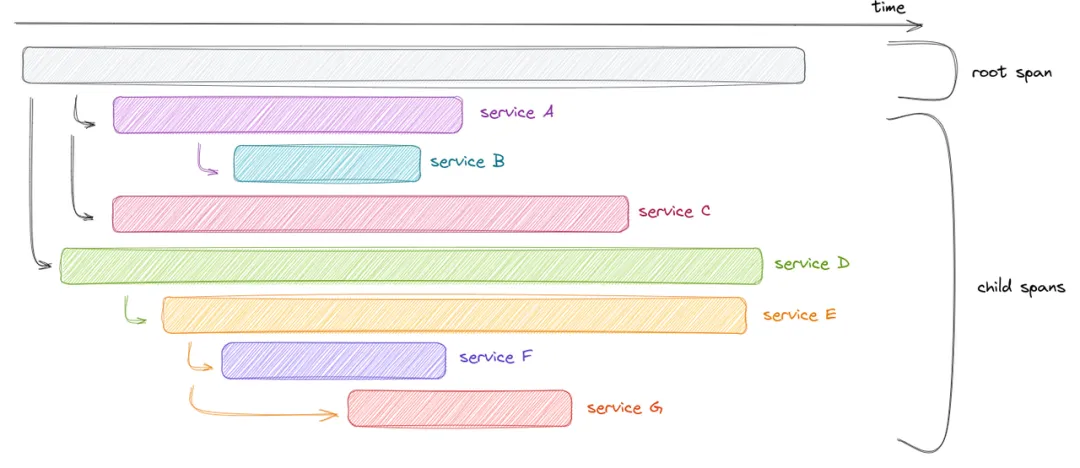
OpenTelemetry 进一步对追踪链路的埋点、收集和导出进行了标准化。OpenTelemetry 内容繁杂且发展历程较长,容易使人产生困惑。实际上,可将其视为一种简单的宽事件生成工具。事实上,(除非需要自建存储后端)无需了解 Otel Collector、Baggage、Resources等概念。
可直接选择适合相应语言的分发版(SDK),配置好自动采集输入输出类事件,随后研究如何向 span 添加自定义属性(需牢记,span 即为宽事件)。
Node.js 示例:
java
app.post('/articles', async (c) => {
const currentSpan = trace.getSpan(context.active());
try {
const body = await c.req.json();
const { title, content } = body;
const user = database.getUser(c.get("userId"));
currentSpan.setAttributes(user);
const article = {
id: uuidv4(),
title,
content,
ownerId: user.id,
published: true,
};
const savedArticle = await database.saveArticle(article);
currentSpan.setAttributes(savedArticle);
const cacheResponse = await cache.set(savedArticle.id, savedArticle);
currentSpan.setAttributes(cacheResponse);
const response = { message: 'Article created', article };
return c.json(response, 201);
} catch (error) {
currentSpan.recordException(error);
return c.json({ error: 'Internal Error' }, 500);
}
});这样可以去除大量样板代码,业务逻辑更清晰。OpenTelemetry 负责记录时间、环境、请求头、trace/span ID等,并能将数据发往第三方或自建服务端。
常见误区与澄清
宽事件能替代所有指标吗?
- 否。您无法用宽事件替代 Kafka 服务器的 CPU 指标。在极端情况下,您也可以完全使用宽事件,但就基础设施而言,指标更为高效且成本更低。宽事件更适用于复杂业务逻辑场景,尤其是应对“未知的未知”(unknown unknowns)问题。对于应用层,您应使用宽事件替代所有业务指标。
宽事件只适用于故障场景?
- 事实并非如此。宽事件的最大价值在于其丰富的上下文信息。笔者观察到诸多产品团队运用宽事件开展产品分析工作,仅仅是因为这套观测工具具备更强的功能。限制宽事件大规模应用于产品分析的因素仅仅是数据保留期限问题:产品分析通常需要超过一年的数据,而观测工作一般并不需要如此长的数据保留时间。
每个服务只能发一个宽事件?
- 前文提及“每个服务节点发送一个(事件)”,此并非强制性要求。针对每个请求,每个服务可发送任意数量的宽事件。理想情形下,发送一条宽事件即可;但在某些场景中,发送多条宽事件亦完全可行。需注意的是,不应将宽事件简化为仅包含三四个字段的小事件,同时应避免事件间出现重复数据。
日志、指标、链路追踪三大支柱论?
- 此观点早已被推翻。可观测性的本质在于具备解答有关系统最为罕见问题的能力。日志、指标、追踪、宽事件、错误等,其本质均为“数据”,应当能够依据需求进行灵活查询。在数据分析领域,并未提及“支柱”这一概念,那么为何可观测性却要有“支柱”之说呢?
结构化日志等同于宽事件?
- 并非如此。结构化日志可能呈现为宽事件,但并非必然。仅有五个字段的结构化日志显然不属于宽事件范畴。缺乏上下文信息的日志同样不能算作宽事件。例如,仅记录响应内容而未包含请求细节(如请求头、路径、方法、请求体)的日志,即便其输出内容丰富,但因缺乏必要的上下文,仍然无法解决“未知的未知”问题。
OpenTelemetry 是现代分布式追踪唯一方式?
- 并非如此。我建议采用分布式追踪,但该技术存在诸多问题。目前,其发展态势过于庞大繁杂,试图“万能适配”各类用户需求,反而导致局面有些失控。应用埋点的难度不应超过应用本身的编写难度。市场上部分产品有自身的解决方案,其核心在于传播上下文并记录时间,以此也能够实现追踪功能。
综上所述,一旦使用宽事件对复杂 Bug 进行过一次定位,你将不再留恋通过 grep 日志或面对各种指标发愁的时光。借助宽事件,用户能够直接聚焦问题的根本原因,而非始终围绕“症状”徘徊。
关于 Greptime
Greptime 格睿科技专注于打造新一代可观测性数据库,服务开发者与企业用户,覆盖从从边缘设备到云端企业级部署的多样化需求。
- GreptimeDB 开源版:开源、云原生,统一处理指标、日志和追踪数据,适合中小规模 IoT,个人项目与可观测性场景;
- GreptimeDB 企业版:面向关键业务,提供更高性能、高安全性、高可用性和智能化运维服务;
- GreptimeCloud 云服务:全托管云服务,零运维体验“企业级”可观测性数据库,弹性扩展,按需付费。
欢迎加入开源社区参与贡献与交流!推荐从带有 good first issue 标签的任务入手,一起共建可观测未来。
⭐ Star us on GitHub | 📚 官网 | 📖 文档

